팔로우 기능은 관계 row 하나를 저장하면 끝나는 기능처럼 보입니다. 하지만 운영 관점에서 먼저 흔들리는 값은 보통 관계 자체가 아니라 프로필에 노출되는 팔로워 수입니다. 관계 테이블에는 row가 있는데 count가 맞지 않거나, 이미 존재하는 관계인데 같은 요청이 다시 들어와 count만 한 번 더 증가하는 식의 문제가 생길 수 있습니다.
팔로우 카운트가 어긋나는 문제는 Redis를 붙였는지 여부보다 먼저, 어떤 값이 원본이고 어떤 값이 조회 최적화를 위한 파생 값인지 정하는 문제였습니다. 관계 row, count 컬럼, 캐시 값이 동시에 존재하는 순간 세 값은 언제든 다른 시점의 데이터를 보여줄 수 있습니다. 아래에서는 그 불일치를 전제로 트랜잭션·제약·락·캐시·복구 경로를 어디까지 나눠야 하는지 정리합니다.
팔로우 수 불일치가 생기는 기본 흐름

팔로우 기능에서 데이터는 크게 두 종류로 나뉩니다.
- 원본 데이터: 누가 누구를 팔로우하는지 나타내는 관계 row
- 파생 데이터: 사용자 프로필에 빠르게 보여주기 위해 저장해 둔 팔로워 수와 팔로잉 수
문제는 파생 데이터가 원본 데이터와 항상 함께 움직여야 한다는 점입니다. 관계 row가 생겼다면 count도 증가해야 하고, 관계 row가 삭제됐다면 count도 감소해야 합니다. 둘 중 하나만 성공하면 사용자가 보는 숫자는 실제 관계와 달라집니다.
가장 단순한 구현은 아래와 같은 순서를 따릅니다.
- 현재 팔로워 수를 읽습니다.
- 애플리케이션 메모리에서 값을 1 증가시킵니다.
- 팔로우 관계 row를 저장합니다.
- 증가한 count를 다시 저장합니다.
단일 요청에서는 자연스럽게 동작합니다. 하지만 같은 대상에게 동시에 팔로우 요청이 들어오면 이 흐름은 바로 lost update 문제로 이어질 수 있습니다.
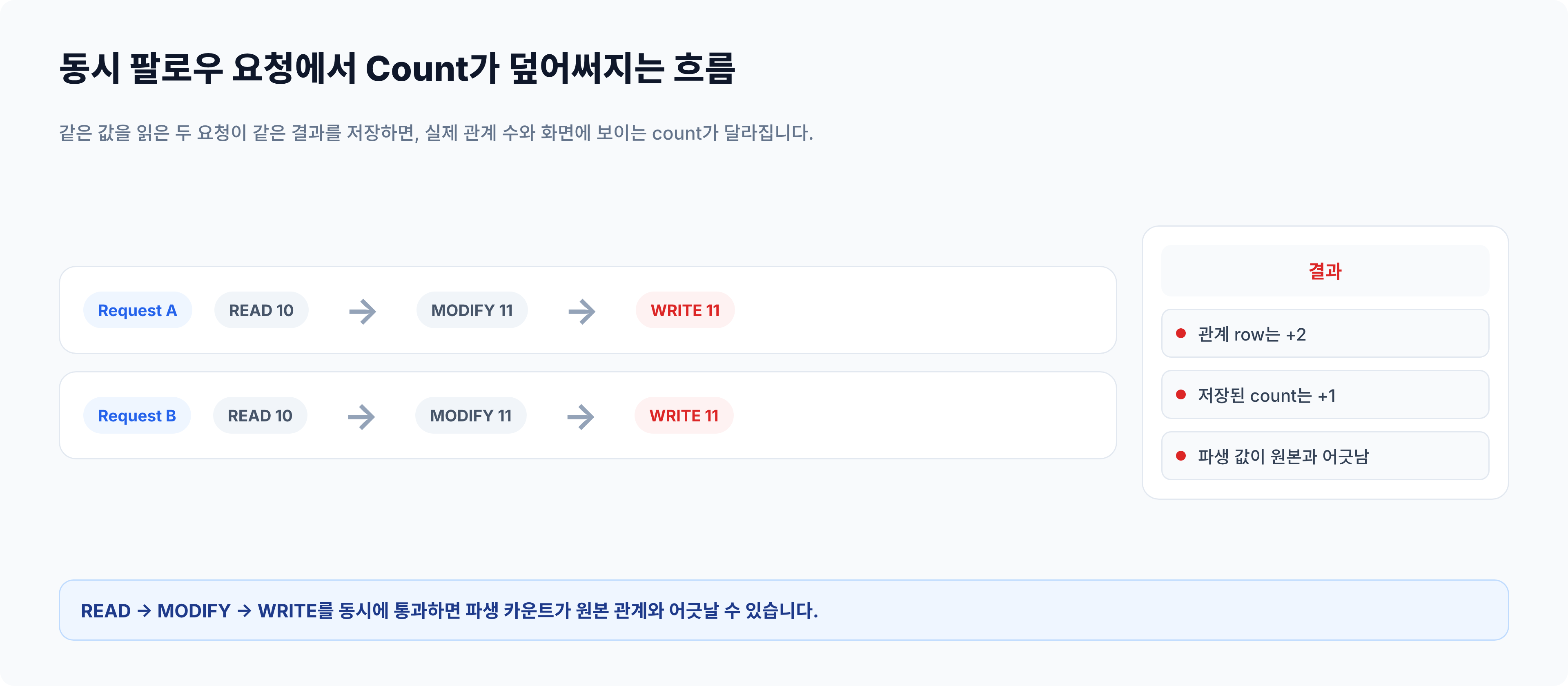
두 트랜잭션이 모두 follower count 10을 읽고 각각 11을 저장하면, 실제 관계 row는 두 건 늘었는데 count는 1만 증가한 것처럼 남을 수 있습니다. 이 문제의 핵심은 “동시 요청이 있다”가 아니라, READ -> MODIFY -> WRITE 구간이 여러 요청에 동시에 열려 있다는 점입니다.
public void follow(Long followerId, Long followingId) {
User follower = userRepository.findById(followerId).orElseThrow();
User following = userRepository.findById(followingId).orElseThrow();
following.increaseFollowerCount();
follower.increaseFollowingCount();
followRepository.save(new Follow(follower, following));
userRepository.save(follower);
userRepository.save(following);
}이 코드는 읽기는 쉽지만, 동시에 실행될 때 어떤 요청의 증가분이 최종 row에 반영되는지 보장하지 못합니다.
먼저 원본과 파생 값을 분리해서 봐야 합니다
팔로워 수와 팔로잉 수는 사용자가 자주 보는 값이라 별도 컬럼으로 저장하고 싶어집니다. 매번 관계 테이블을 COUNT(*)로 집계하면 사용자가 많아질수록 비용이 커지기 때문입니다. 하지만 count 컬럼은 원본이 아니라 관계 row에서 계산 가능한 파생 값입니다.
이 기준을 먼저 세워야 장애가 났을 때 판단이 빨라집니다.
| 데이터 | 역할 | 정합성 기준 |
|---|---|---|
| follow relationship | 팔로우 관계의 원본 | 중복 관계가 없어야 함 |
| follower_count | 조회 최적화를 위한 파생 값 | 관계 row 기준 집계와 맞아야 함 |
| Redis cache | 반복 조회 완화 | 원본 불일치 해결책으로 보지 않음 |
트랜잭션은 필요하지만 충분하지 않았습니다
팔로우 관계 저장과 count 갱신은 하나의 트랜잭션으로 묶여야 합니다. 관계 row만 저장되고 count가 증가하지 않는 상태, 또는 count만 증가하고 관계 row가 저장되지 않는 상태를 막아야 하기 때문입니다.

@Transactional
public void follow(Long followerId, Long followingId) {
User follower = userRepository.findById(followerId).orElseThrow();
User following = userRepository.findById(followingId).orElseThrow();
followRepository.save(new Follow(follower, following));
follower.increaseFollowingCount();
following.increaseFollowerCount();
}하지만 @Transactional만으로 lost update가 사라지는 것은 아닙니다. 트랜잭션은 여러 작업을 하나의 커밋 단위로 묶어주지만, 서로 다른 트랜잭션이 같은 row를 어떤 순서로 수정할지까지 자동으로 정리해주지는 않습니다.
중복 요청은 예외가 아니라 정상 입력처럼 다뤄야 합니다
사용자가 버튼을 한 번만 누른다고 가정하면 안 됩니다. 느린 네트워크, 프론트엔드 중복 클릭, 재시도 로직 때문에 같은 팔로우 요청이 두 번 이상 들어올 수 있습니다. 서버 입장에서는 중복 요청도 정상 입력처럼 다뤄야 합니다.
첫 번째 방어선은 애플리케이션 코드가 아니라 DB 제약입니다.
CREATE TABLE follow_relationship (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
follower_id BIGINT NOT NULL,
following_id BIGINT NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
UNIQUE KEY unique_follow_pair (follower_id, following_id),
INDEX idx_following_created (following_id, created_at),
INDEX idx_follower_created (follower_id, created_at)
);exists 조회로 먼저 확인하더라도, 동시에 두 요청이 들어오면 둘 다 “아직 없다”고 판단한 뒤 insert를 시도할 수 있습니다. 최종 방어선은 결국 (follower_id, following_id) 유니크 제약이어야 합니다.
그다음 기준은 count 갱신 시점입니다.
- insert가 실제로 성공한 경우에만 count를 증가시킵니다.
- 이미 존재하는 관계라면 성공 응답을 줄 수는 있어도 count를 다시 증가시키지 않습니다.
- unfollow도 실제 삭제된 row가 있을 때만 count를 감소시킵니다.
이 기준을 두면 같은 요청이 여러 번 들어와도 최종 상태가 달라지지 않습니다. 팔로우 기능은 “요청 횟수”가 아니라 “관계의 최종 상태”를 기준으로 설계해야 합니다.
count 갱신은 원자적 update를 우선 검토할 수 있습니다
카운트를 엔티티로 읽어 온 뒤 메모리에서 증가시키면 lost update 가능성이 커집니다. 단순 증가·감소만 필요하다면 DB의 원자적 update를 사용하는 편이 더 명확할 수 있습니다.
UPDATE users
SET follower_count = follower_count + 1
WHERE id = :following_id;JPA에서도 별도 update query로 표현할 수 있습니다.
@Modifying
@Query("UPDATE User u SET u.followerCount = u.followerCount + 1 WHERE u.id = :userId")
int increaseFollowerCount(@Param("userId") Long userId);이 방식은 READ -> MODIFY -> WRITE 구간을 줄입니다. 다만 update가 성공해야 할 조건과 관계 row insert 성공 여부를 같은 트랜잭션 안에서 묶어야 합니다. count만 먼저 올리고 관계 row insert가 실패하면 다시 불일치가 생깁니다.
@Transactional
public void follow(Long followerId, Long followingId) {
boolean inserted = followRepository.insertIgnore(followerId, followingId) == 1;
if (!inserted) {
return;
}
userRepository.increaseFollowingCount(followerId);
userRepository.increaseFollowerCount(followingId);
}실제 구현에서는 사용하는 DB와 JPA 전략에 따라 insert ignore, duplicate key 예외 처리, native query 여부를 선택해야 합니다. 관계 생성 성공 여부가 count 변경의 조건이 되어야 하고, 실패한 관계 생성이 count 증가로 남지 않도록 같은 트랜잭션 경계에서 처리해야 합니다.
락 전략은 충돌 빈도와 재시도 비용으로 골라야 합니다
동시성 제어에서 자주 비교하는 선택지는 비관적 락과 낙관적 락입니다. 둘 중 하나가 항상 정답은 아닙니다.
| 전략 | 동작 방식 | 적합한 상황 | 주의점 |
|---|---|---|---|
| 비관적 락 | 수정 전에 row를 잠금 | 같은 대상에 충돌이 자주 발생 | 대기 시간과 데드락 가능성 |
| 낙관적 락 | 수정 시점에 version 충돌 감지 | 대부분 충돌이 드문 요청 | 충돌 시 재시도 설계 필요 |
| 원자적 update | DB에서 count를 직접 증가·감소 | 단순 카운터 변경 | 관계 row 성공 여부와 함께 묶어야 함 |
비관적 락은 충돌을 먼저 막습니다.
@Lock(LockModeType.PESSIMISTIC_WRITE)
@Query("SELECT u FROM User u WHERE u.id = :id")
Optional<User> findByIdWithPessimisticLock(@Param("id") Long id);같은 사용자의 count를 여러 요청이 동시에 수정하는 상황에서는 직관적입니다. 대신 요청이 몰리면 대기 시간이 늘고, 여러 row를 함께 잠글 때는 데드락 가능성이 생깁니다.
낙관적 락은 충돌을 나중에 감지합니다.
@Entity
public class User {
@Id
private Long id;
private int followerCount;
@Version
private Long version;
}대부분의 요청이 서로 다른 사용자를 대상으로 한다면 처리량 측면에서 유리할 수 있습니다. 하지만 version 충돌이 발생했을 때 재시도할지, 사용자에게 실패를 돌려줄지, 재시도 횟수를 어디까지 둘지 결정해야 합니다.
데드락은 락을 쓰는 순간 함께 설계해야 합니다
팔로우는 두 사용자의 count를 함께 바꾸는 경우가 많습니다. follower의 following count와 following의 follower count를 모두 수정한다면, 두 row에 대한 락 순서가 중요해집니다.
예를 들어 A가 B를 팔로우하고, 동시에 B가 A를 팔로우하는 요청이 들어오면 다음 상황이 생길 수 있습니다.
- 트랜잭션 1은 A를 먼저 잠그고 B를 기다립니다.
- 트랜잭션 2는 B를 먼저 잠그고 A를 기다립니다.
- 두 트랜잭션이 서로의 락을 기다리며 데드락이 발생합니다.
방어 기준은 단순합니다. 여러 user row를 잠글 수 있다면, 항상 같은 순서로 잠급니다.
@Transactional
public void followWithOrderedLock(Long followerId, Long followingId) {
Long firstId = Math.min(followerId, followingId);
Long secondId = Math.max(followerId, followingId);
User first = userRepository.findByIdWithPessimisticLock(firstId).orElseThrow();
User second = userRepository.findByIdWithPessimisticLock(secondId).orElseThrow();
// first, second에서 실제 follower/following 역할을 다시 매핑한 뒤 count를 변경합니다.
}락을 도입하면 정합성은 좋아질 수 있지만, 락 순서를 정하지 않으면 운영 문제는 다른 형태로 남습니다.
Redis는 원본 정합성보다 조회 부하 완화에 가깝습니다
팔로워 목록이나 팔로워 수는 자주 조회됩니다. 그래서 Redis를 붙이고 싶어지는 지점이 많습니다. 다만 Redis를 count의 원본으로 두는 순간, DB 관계 row와 Redis 값 사이의 정합성 문제를 다시 풀어야 합니다.

읽기 경로에서는 Look-Aside 캐시가 유용합니다.
public List<UserSummary> getFollowers(Long userId) {
String cacheKey = "followers:" + userId;
List<UserSummary> cached = redisTemplate.opsForList().range(cacheKey, 0, -1);
if (cached != null && !cached.isEmpty()) {
return cached;
}
List<UserSummary> followers = followRepository.findFollowersByUserId(userId);
redisTemplate.opsForList().rightPushAll(cacheKey, followers);
redisTemplate.expire(cacheKey, Duration.ofMinutes(30));
return followers;
}이 방식은 반복 조회 부담을 줄이는 데는 효과적입니다. 하지만 관계 생성과 count 갱신의 정합성을 보장하지는 않습니다. 그래서 Redis는 다음 위치에 두는 편이 안전합니다.
- 원본 관계와 count는 DB 트랜잭션 안에서 갱신합니다.
- Redis는 조회 결과나 count 표시값을 짧은 TTL로 캐시합니다.
- 팔로우·언팔로우 성공 후 관련 캐시를 무효화합니다.
- 캐시 값이 원본과 다를 수 있다는 전제를 두고 재계산 경로를 남깁니다.
캐시 무효화 시점도 중요했습니다. DB 트랜잭션이 커밋되기 전에 캐시를 먼저 지우면, 이어지는 조회가 아직 커밋되지 않은 상태를 기준으로 다시 캐시를 채울 수 있습니다. 반대로 커밋 이후 무효화가 실패하면 오래된 count가 잠시 노출될 수 있습니다. 그래서 캐시 무효화는 트랜잭션 커밋 이후 실행되는 후처리로 분리하는 편이 안전하고, 실패해도 짧은 TTL과 재계산 경로로 회복될 수 있어야 합니다. 캐시는 정합성의 원본이 아니라 조회 보조 계층이라는 전제를 계속 유지해야 했습니다.
Write-Back처럼 Redis에 먼저 쓰고 나중에 DB에 반영하는 방식은 쓰기 부하를 줄일 수 있지만, 사용자 화면에 바로 드러나는 관계 데이터에는 더 조심해야 합니다. 장애나 재시도 중간에 캐시와 DB가 어긋나는 시간을 허용해야 하기 때문입니다.
복구 경로는 운영 기능으로 남겨야 합니다
동시성 방어를 넣어도 이미 어긋난 count가 없어진다고 볼 수는 없습니다. 과거 버그, 수동 데이터 수정, 배치 실패, 예외 처리 누락으로 파생 값이 원본과 다를 수 있습니다. 그래서 reconciliation 쿼리가 필요합니다.
SELECT u.id,
u.follower_count AS stored_count,
COUNT(fr.id) AS actual_count
FROM users u
LEFT JOIN follow_relationship fr ON fr.following_id = u.id
GROUP BY u.id, u.follower_count
HAVING u.follower_count <> COUNT(fr.id);이 쿼리는 실시간 방어 장치가 아닙니다. 원본 관계 row를 기준으로 count 불일치를 찾는 운영용 기준입니다. 불일치가 확인되면 다음처럼 복구할 수 있습니다.
UPDATE users u
SET follower_count = (
SELECT COUNT(*)
FROM follow_relationship fr
WHERE fr.following_id = u.id
)
WHERE u.id IN (:target_user_ids);운영에서는 이 작업을 임시 SQL로만 남겨두기보다, 점검 스크립트나 관리용 배치로 남기는 편이 안전합니다. 파생 값을 저장하는 구조라면 “정합성을 지키는 경로”와 “정합성을 다시 맞추는 경로”가 함께 있어야 합니다.
관측해야 할 지표도 명확했습니다
팔로우 count 정합성은 단순히 테스트 몇 개로 끝나기 어렵습니다. 운영 중에는 충돌 빈도와 재시도, 캐시 무효화 실패를 함께 봐야 합니다.
| 지표 | 확인하려는 것 |
|---|---|
| duplicate key 발생 수 | 중복 요청이 얼마나 들어오는지 |
| lock wait time | 비관적 락으로 인한 대기 시간이 과도한지 |
| optimistic lock retry 수 | 낙관적 락 재시도가 정상 범위인지 |
| count mismatch 검출 수 | 원본 관계와 파생 count가 어긋나는지 |
| cache invalidation 실패 수 | Redis 캐시가 오래된 값을 유지하는지 |
특히 count mismatch는 0이어야 한다고 선언하기보다, 발견했을 때 어떤 원인으로 생겼는지 추적할 수 있어야 합니다. 유니크 제약 위반인지, count update 누락인지, 캐시 갱신 지연인지에 따라 해결 지점이 다르기 때문입니다.
원본과 파생 값을 다시 맞추는 기준
팔로우 count 문제는 Redis나 캐시의 문제가 아니라, 원본 관계와 파생 값을 함께 저장하는 데이터 모델의 문제였습니다. 관계 row와 count 컬럼을 동시에 유지하는 순간, 시스템은 두 값이 어긋날 수 있는 지점을 직접 관리해야 합니다.
이후 운영 기준은 원본과 파생 값을 먼저 나눠 보는 쪽으로 정리했습니다. 원본은 follow relationship row이고, count는 조회 최적화를 위한 파생 값입니다. 중복 팔로우는 애플리케이션 체크보다 DB 유니크 제약으로 막고, count는 관계 생성·삭제가 실제로 성공한 경우에만 변경합니다. 동시 수정이 많은 경로에서는 트랜잭션만으로 충분한지, 원자적 update나 락 전략이 필요한지까지 함께 봐야 합니다.
Redis는 이 기준의 바깥에 둡니다. Redis는 조회 부하를 줄이는 보조 경로일 수는 있지만, 원본 정합성을 대신 보장하지는 않습니다. 캐시가 오래된 값을 보여줄 수 있다는 전제를 두고 TTL, 무효화, 재계산 경로를 함께 남겨야 합니다.
여기서 조심해야 할 표현은 “동시성 문제를 완전히 없앴다”입니다. 실제로 한 일은 원본과 파생 값을 분리하고, 어긋나기 어려운 쓰기 경로와 어긋났을 때 다시 맞출 수 있는 복구 경로를 함께 둔 것입니다. 파생 값을 저장하는 순간 정합성은 구현 한 번으로 끝나지 않습니다. mismatch를 발견했을 때 유니크 제약 위반인지, count update 누락인지, 커밋 이후 캐시 무효화 실패인지, 단순 캐시 갱신 지연인지 추적할 수 있어야 운영 가능한 구조가 됩니다.