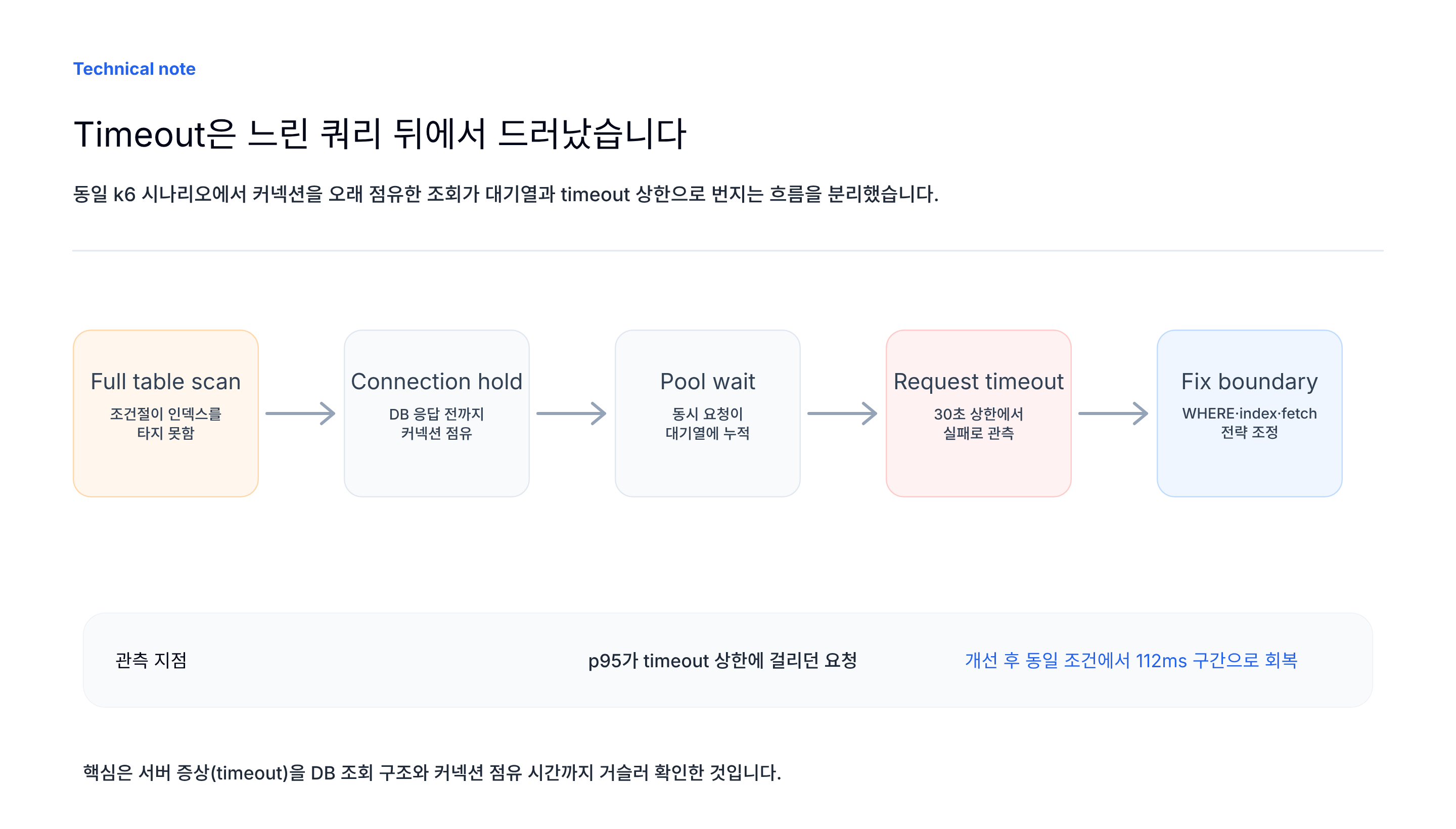
MVP 출시 직후 부하 테스트에서 먼저 확인하려던 것은 단순한 최대 처리량이 아니었습니다. 더 필요한 질문은 어느 자원이 먼저 포화되고, 그 포화가 어떤 경로로 사용자 응답 시간에 번지는가였습니다.
테스트 환경은 t2.micro급의 작은 인스턴스였고, 30 VUs 조건에서 가장 먼저 무너진 지점은 애플리케이션 CPU가 아니라 DB 커넥션 풀이었습니다. 다만 커넥션 풀 자체가 원인은 아니었습니다. 느린 쿼리가 커넥션을 오래 점유했고, 그 결과 뒤따르는 요청들이 커넥션을 얻지 못한 채 대기하다 timeout에 도달했습니다.
처음부터 스케일업을 선택하지 않은 이유도 여기에 있습니다. 인스턴스를 키우면 증상은 늦게 나타날 수 있지만, 쿼리가 커넥션을 오래 붙잡는 구조는 그대로 남습니다. 그래서 이번 정리는 “k6로 몇 ms까지 줄였다”는 결과보다, timeout이 발생한 흐름을 쿼리 실행 방식과 커넥션 점유 시간으로 좁혀간 과정에 초점을 둡니다.
테스트 환경
수치를 해석하려면 먼저 테스트 조건을 고정해야 합니다. 같은 API라도 데이터 규모, 커넥션 풀 크기, 인스턴스 수가 달라지면 결과를 비교하기 어렵기 때문입니다. 이번 테스트는 아래 조건을 기준으로 진행했습니다.
| 항목 | 구성 |
|---|---|
| 아키텍처 | Nginx (least_conn) → Spring Boot(CPU Core 1, memory 1GB) × 2 |
| 최대 동시 사용자 | 30 VUs (Virtual Users) |
| 테스트 시나리오 | 추천 API(100%) + 인기 API(50%) + 필터 API(40%) |
| HikariCP Pool Size | 10 (인스턴스당) |
| 테스트 데이터 | 회원 10,000명, 매칭 29,999건 |
| 모니터링 | Prometheus + Grafana + InfluxDB |
| 부하 테스트 도구 | k6 |
부하 테스트 도구는 k6를 사용했습니다. 시나리오를 코드로 남길 수 있어 같은 조건을 반복하기 쉽고, 테스트 스크립트 자체의 오버헤드도 낮아 작은 인스턴스 환경에서 병목을 관찰하기에 적합했습니다.
측정 전에 먼저 고정한 해석 기준
부하 테스트 수치는 단독으로 결론이 되기 어렵습니다. p95가 높다는 사실만으로 CPU가 부족하다고 말할 수 없고, 에러율이 높다는 사실만으로 커넥션 풀 크기만 늘려야 한다고 볼 수도 없습니다. 같은 timeout이라도 원인은 느린 쿼리, 커넥션 대기, GC pause, 외부 I/O, 재시도 폭주처럼 여러 경로로 갈라질 수 있습니다.
그래서 이번 테스트에서는 수치를 먼저 개선하기보다, 각 지표가 어떤 질문에 답하는지부터 정했습니다. 특히 30초 timeout은 평균 응답 시간이 아니라 요청이 정상 응답 구간을 벗어나 상한에 걸렸다는 신호로 봤습니다. 이 기준을 정해두면 개선 후 수치를 해석할 때도 “30초가 112ms가 됐다”보다 “timeout 상한에 걸리던 요청이 정상 응답 분포 안으로 돌아왔다”에 가깝게 읽을 수 있습니다.
| 지표 | 답하려는 질문 | 주의해서 본 점 |
|---|---|---|
| p95 / p99 | 상위 지연 구간이 어디서 무너지는가? | timeout 상한에 걸린 값은 실제 평균 처리 시간처럼 해석하지 않았습니다. |
| Connection Acquire Time | 요청이 쿼리 실행 전에 커넥션을 기다리는가? | 느린 쿼리보다 커넥션 대기가 응답 시간을 지배하는 구간을 분리했습니다. |
| Hikari active / idle / waiting | 커넥션 풀이 포화됐는가? | pool size 자체보다 커넥션을 오래 붙잡는 작업을 함께 봤습니다. |
| GC / Heap | 메모리 압박이 요청 지연을 만들었는가? | Full GC와 pause time이 timeout을 설명할 수준인지 확인했습니다. |
| Thread State | CPU 계산보다 I/O 대기가 큰가? | Runnable 증가와 Waiting 증가를 구분해 CPU 병목으로 단정하지 않았습니다. |
이 기준을 먼저 고정한 덕분에 이후 단계에서도 “수치가 좋아졌는가”보다 “어떤 병목 경계가 줄었는가”를 중심으로 비교할 수 있었습니다.
Baseline 측정
초기 상황
첫 단계에서는 개선보다 관찰에 집중했습니다. 인덱스나 쿼리 구조를 먼저 건드리면 어떤 변화가 효과를 냈는지 분리하기 어렵습니다. 그래서 기본 설정에 가까운 상태에서 부하를 걸고, 에러율과 응답 시간 분포가 어디서 무너지는지 먼저 확인했습니다.
| 지표 | 측정값 | 목표 | 평가 |
|---|---|---|---|
| 에러율 | 33.3% (636/1910) | < 5% | 목표 미달 |
| p50 응답시간 | 8,709ms (8.7초) | < 200ms | 목표 미달 |
| p95 응답시간 | 30,001ms (Timeout) | < 500ms | 목표 미달 |
| p99 응답시간 | 30,001ms | < 1,000ms | 목표 미달 |
| Max 응답시간 | 30,013ms | - | Timeout 도달 |
API별 상세 분석
| API | p95 응답시간 | 분석 |
|---|---|---|
추천 API (/recommendations) | 27,536ms (27.5초) | 인덱스 없는 복합 조건 쿼리로 Full Scan |
인기 API (/popular) | 28,507ms (28.5초) | GROUP BY + ORDER BY로 임시 테이블 생성 |
필터 API (/filters) | 30,001ms (Timeout) | 동적 필터 조건으로 가장 느림 |
원인 분석
Grafana 대시보드와 애플리케이션 로그를 함께 보니, 응답 지연은 단순히 CPU가 부족해서 생긴 문제가 아니었습니다. 요청들은 DB 작업을 기다리며 커넥션을 오래 점유했고, 그 결과 DB 커넥션 풀 고갈이 먼저 나타났습니다.
1. DB 커넥션 풀 고갈 (Saturation Point)
로그 확인 결과, 최대 커넥션 10개가 모두 사용 중인 상태에서 대기열이 해소되지 못하고 있었습니다.
HikariPool-1 - Connection is not available, request timed out after 30000ms
(total=10, active=10, idle=0, waiting=7)이 상태는 커넥션 풀이 이미 포화된 상황에 가까웠습니다. 처리 속도보다 유입 속도가 빨라지면 대기열이 줄어들지 못하고, 새 요청은 커넥션을 얻기 위해 계속 기다립니다. 결국 Connection Acquire Time이 timeout 설정값에 도달하면서 정상 처리보다 대기 시간이 응답 시간을 지배하게 됐습니다.
2. 근본 원인은 느린 쿼리 (Slow Query)
커넥션을 오래 붙잡고 있던 직접적인 원인은 인덱스를 제대로 활용하지 못한 조회였습니다. 데이터 규모가 크지 않은 상태에서도 주요 API 조회가 27~30초까지 늘어났고, 그동안 커넥션은 반환되지 않았습니다. 쿼리 하나가 커넥션을 오래 점유하면 pool size가 10이어도 동시 요청을 감당하기 어렵습니다. 이 단계의 병목은 “커넥션 수가 부족하다”보다 먼저, 커넥션을 오래 붙잡는 쿼리 구조에 있었습니다.
GC는 1차 병목이 아니었습니다
GC(Garbage Collection) 가능성도 함께 확인했습니다.
| 지표 | 결과 |
|---|---|
| Full GC 발생 | 0회 |
| Minor GC 시간 | 86~92ms (정상) |
| Heap 사용량 | 130~340MB (안정) |
확인 결과, 이번 병목의 1차 원인은 GC가 아니었습니다.
GC가 응답 지연에 영향을 줄 수 있는 이유는 Stop-the-World(STW) 때문입니다. GC가 수행되는 동안 애플리케이션 스레드가 멈추기 때문에 pause time이 길어지면 요청 지연으로 이어질 수 있습니다. 그래서 응답 시간이 길어졌을 때 GC 지표도 함께 확인했습니다.
Grafana의 GC Pause Duration 그래프는 25ms 이하로 안정적으로 유지됐습니다. G1GC가 일반적으로 목표로 삼는 pause time 범위와 비교해도, 해당 테스트 구간의 GC 지연은 30초 timeout을 설명하기 어려웠습니다.
Heap 사용량도 130~340MB 범위에서 안정적으로 유지됐습니다. 최소한 이 테스트 구간에서는 메모리 사용량 증가나 Full GC 반복이 응답 지연을 설명하지 못했습니다.
따라서 이 단계에서 먼저 손봐야 할 대상은 GC 옵션이 아니라 쿼리 실행 시간과 커넥션 점유 시간이었습니다.
CPU 스파이크는 원인보다 결과에 가까웠습니다
테스트 중 CPU 사용률도 함께 올라갔습니다. 하지만 처리량은 낮고 timeout은 계속 발생했습니다. 이 경우 CPU 상승을 곧바로 “연산량이 많다”로 해석하면 위험합니다. 실제로는 실패 처리, 스레드 전환, 대기 상태 해소 과정에서 CPU가 소모될 수 있기 때문입니다.
로그와 스레드 덤프를 함께 확인하니, CPU 사용률 상승은 다음 작업들이 겹치며 나타난 결과에 가까웠습니다.
- 과도한 Context Switching: 커넥션을 얻기 위해 대기하는 스레드(Waiting)와 깨어나는 스레드 간의 전환 비용
- 예외 처리 비용: 초당 수십 건씩 발생하는
ConnectionTimeoutException객체 생성 및 스택 트레이스 로깅 - 재시도(Retry) 로직: 실패한 요청을 다시 시도하며 부하 가중
즉, CPU 상승은 병목의 출발점이라기보다 DB 커넥션 고갈 이후에 나타난 2차 증상에 가까웠습니다. 이 판단 덕분에 CPU 튜닝이나 인스턴스 증설보다 쿼리 구조와 커넥션 점유 시간을 먼저 보게 됐습니다.
Phase 1. 인덱스 활용과 조기 종료
숨겨진 병목과 인덱스 미활용
Baseline 이후에는 먼저 쿼리가 왜 오래 걸리는지 확인했습니다. 코드와 실행 계획을 함께 보니 병목은 크게 두 군데에서 드러났습니다.
- 메모리 순회 기반 Full Scan: 조건에 맞는 일부 사용자를 찾기 위해 1,000명의 회원을 애플리케이션 메모리에서 순회하며 점수를 계산하고 있었습니다.
- 복합 인덱스 선행 컬럼 누락: DB에는
(status, university_id, college_id, created_at DESC)순으로 복합 인덱스가 걸려 있었습니다. 하지만 실제 쿼리에는 status 조건이 빠져 있어, 인덱스의 첫 번째 컬럼을 건너뛰는 구조였습니다. 이 때문에 설계한 인덱스가 조회 경로에서 제대로 활용되지 못했습니다.
인덱스 활용과 루프 종료
먼저 Repository에 status 조건을 추가해 복합 인덱스의 선행 컬럼을 쿼리 조건에 포함시켰습니다.
// Before: 인덱스 미활용 (status 조건 누락)
Page<Member> findByUniversityIdAndIdNot(Long universityId, Long memberId, Pageable pageable);
// After: 선행 컬럼을 포함해 인덱스 활용
@Query("SELECT m FROM Member m WHERE m.status = :status " + // 선행 컬럼 명시
"AND m.university.id = :universityId AND m.id != :memberId " +
"ORDER BY m.createdAt DESC")
Page<Member> findActiveByUniversityIdAndIdNot(
@Param("status") MemberStatus status,
@Param("universityId") Long universityId,
// ... params
);또한 1,000명을 모두 계산하지 않고, 상위 30명(Candidate Buffer)만 확보되면 루프를 즉시 탈출하도록 조기 종료 로직을 추가했습니다.
테스트 결과
이 변경만 놓고 보면 응답 시간이 줄어야 했습니다. 조회 범위를 줄였고, 인덱스를 활용하도록 조건도 맞췄기 때문입니다. 하지만 부하 테스트에서는 기대한 만큼 병목이 줄지 않았습니다.
| 지표 | Baseline (Phase 0) | Phase 1 (Index+Logic) | 변화 |
|---|---|---|---|
| 총 요청 | 1,910건 | 770건 | ↓ 60% |
| 에러율 | 33.3% | 62.2% | 2배 증가 |
| p50 응답 | 8.7s | 20.0s | 증가 |
| p95 응답 | 30.0s | 30.0s | Timeout 지속 |
조회 범위는 줄었지만 커넥션 경합은 남았습니다
표면적으로는 조회 범위가 줄었지만, 시스템 전체 병목은 여전히 DB 커넥션 풀(Pool Size=10) 주변에 남아 있었습니다.
- 짧고 빈번한 I/O 요청의 폭주
조기 종료 로직으로 후보 수는 줄었지만, 후보를 처리하는 동안 findByMemberId 같은 조회가 루프 안에서 반복됐습니다. 결과적으로 한 요청 안에서 약 90~100회의 DB 접근이 짧은 시간에 몰렸습니다.
- 경합(Contention) 심화
커넥션 10개가 모두 사용 중인 상태에서 애플리케이션은 짧은 간격으로 새 커넥션을 계속 요구했습니다. 이때 쿼리 하나하나는 조금 빨라졌더라도, 전체 요청 흐름에서는 커넥션을 넘겨받기 위한 대기 시간이 길어졌습니다. 결과적으로 GetConnectionTimeout이 발생할 때까지 스레드가 기다리는 상황이 반복됐습니다.
실제 로그에서도 스레드들이 커넥션을 얻지 못하고 대기하는 상태가 확인됐습니다.
HikariPool-1 - Connection is not available, request timed out after 20000ms
(total=10, active=10, idle=0, waiting=3)이 결과는 쿼리 개수만으로 병목을 설명하기 어렵다는 점을 보여줬습니다. 몇 번 조회했는가뿐 아니라, 커넥션을 어떤 패턴으로 점유했는지가 응답 지연에 더 직접적으로 영향을 줬습니다.
Phase 2. @BatchSize 적용
다음으로는 N+1을 줄이기 위해 JPA의 @BatchSize를 적용했습니다. 지연 로딩된 연관 데이터를 여러 건씩 묶어 가져오면 반복 조회를 줄일 수 있을 것이라고 봤습니다.
@BatchSize(size = 50)
@OneToMany(mappedBy = "member", fetch = FetchType.LAZY)
private List<TimeTable> timeTables;테스트 결과

| 지표 | Phase 1 | Phase 2 (@BatchSize) | 평가 |
|---|---|---|---|
| 에러율 | 62.2% | 57.8% | 미미한 변화 |
| p95 응답 | 30.0s | 30.0s | 여전히 Timeout |
왜 효과가 제한적이었을까?
Hibernate의 @BatchSize는 영속성 컨텍스트가 관리하는 프록시 객체를 탐색하는 Lazy Loading 시점에 동작합니다. 예를 들어 member.getTimeTables().get(0)처럼 연관 객체를 실제로 접근하는 순간에 묶음 조회가 개입할 수 있습니다.
하지만 현재 로직은 서비스 계층에서 명시적으로 Repository 메서드를 호출하고 있었습니다.
// 서비스 코드
timeTableQueryService.findByMemberId(member.getId()); // 직접 호출이 코드는 JPA가 프록시를 탐색하며 연관 객체를 초기화하는 흐름이 아니라, 서비스 계층에서 직접 Repository를 호출하는 흐름이었습니다. 따라서 @BatchSize가 개입할 지점이 거의 없었습니다.
결국 이 문제는 어노테이션 하나로 숨길 수 있는 N+1이 아니었습니다. 루프 안에서 DB를 반복 호출하는 구조 자체를 바꿔야 했습니다.
Phase 3. IN절 일괄 조회로 DB 왕복 줄이기
스레드 상태(Thread State) 분석
Grafana의 스레드 상태 그래프를 분석한 결과, 대부분의 스레드가 Waiting(I/O 대기) 상태였습니다. 이는 CPU 연산보다 DB 응답 대기 시간이 더 큰 I/O Bound 병목에 가까웠습니다. 스레드는 존재했지만 실제로는 DB 응답을 기다리며 묶여 있었습니다.
이 상황에서 스레드 수만 늘리면 대기하는 주체가 늘어날 뿐입니다. 먼저 줄여야 할 것은 DB와 왕복하는 횟수(Round-Trip)였습니다.
적용 내용
루프 안에서 필요한 데이터를 매번 조회하던 구조를, 루프 밖에서 한 번에 가져온 뒤 메모리에서 매핑하는 방식으로 바꿨습니다.
루프 밖에서 일괄 조회
기존 로직은 후보를 순회하며 필요한 데이터를 그때마다 DB에서 가져오는 구조였습니다. 이를 후보 ID를 먼저 모은 뒤 IN 절로 일괄 조회하고, 조회 결과를 Map으로 구성해 메모리에서 매핑하는 방식으로 바꿨습니다.
// Before: 루프 내 쿼리 실행 (N+1 발생)
for (Member m : candidates) {
// 요청당 약 150회의 쿼리가 실행되는 구조
timeTableService.findByMemberId(m.getId());
matchRepository.existsByMatching(currentMember, m);
}
// After: 루프 밖 일괄 조회 (IN 절 사용)
List<Long> ids = candidates.stream().map(Member::getId).toList();
// 2번의 쿼리로 관련 데이터 일괄 조회
Map<Long, List<TimeTable>> timeTables = timeTableRepository.findByMemberIdIn(ids) ...;
Set<Long> matchedIds = matchRepository.findMatchedMemberIds(currentId, ids);
for (Member m : candidates) {
// 메모리에서 O(1) 조회 -> 추가 DB 접근 없이 처리
process(m, timeTables.get(m.getId()), matchedIds.contains(m.getId()));
}이 변경으로 요청당 쿼리 수는 150회 이상에서 3회로 줄었습니다. 쿼리 수 자체보다 더 중요한 변화는 DB 왕복이 루프 안에서 반복되지 않게 됐다는 점이었습니다.
테스트 결과
| 지표 | Before (Phase 2) | After (Phase 3) | 결과 |
|---|---|---|---|
| 순수 로직 시간 | 2000 ms | 50 ~ 180ms | 10배 이상 개선 |
| p95 응답 시간 | 30.0s (Timeout) | 30.0s (Timeout) | 개선 안 됨 |
로직 시간과 응답 시간이 달랐던 이유
이 지점에서 병목이 API 하나에만 갇혀 있지 않다는 사실이 드러났습니다.
- 추천 API는 이제 0.1초 안팎에서 처리가 끝나고, 커넥션도 빠르게 반납했습니다.
- 하지만 테스트 시나리오에는 필터(Filter) API도 함께 포함돼 있었습니다.
- 이 필터 API는 아직 최적화되지 않아, 요청당 수천 개의 쿼리를 실행하며 DB 커넥션을 30초 이상 점유하고 있었습니다.
- DB 커넥션 풀(최대 10개)은 필터 API 요청 몇 개만으로도 포화될 수 있었습니다.
- 정작 빨라진 추천 API 요청이 들어왔을 때는 쓸 수 있는 커넥션이 없어 대기열(Pool Queue)에서 기다리다가 30초 타임아웃에 도달했습니다.
커넥션 풀은 모든 API가 함께 쓰는 공유 자원입니다. 그래서 특정 API 하나가 커넥션을 오래 점유하면, 이미 최적화한 API도 대기열 뒤로 밀릴 수 있었습니다.
Phase 4. 필터 API N+1 및 Fetch Join
필터 API의 N+1 해결
필터 API도 추천 API와 마찬가지로 GROUP BY와 IN 절을 활용하여 최적화했다.
// Before: 루프 돌며 Count 쿼리 실행 (1,000번)
for (Member m : members) { countMatches(m); }
// After: 집계 쿼리로 일괄 조회
Map<Long, Long> matchCounts = matchRepository.countMatchesByMemberIds(memberIds);결과
필터 API N+1 제거 후 커넥션 풀 지표 — 느린 API가 공유 커넥션 풀을 붙잡던 구간이 줄어든 것을 확인한 화면입니다.
| 지표 | 값 | 평가 |
|---|---|---|
| 응답 시간 (p95) | ~10.9s | Timeout(30s)은 사라졌지만 여전히 느림 (목표 미달) |
| 처리량 (RPS) | ~6 req/s | 시스템이 멈추지 않고 동작하기 시작함 (Before: 0) |
| 발견된 문제 | Department N+1 | 필터 API에서 부서 정보를 조회할 때마다 쿼리가 발생함 |
Fetch Join으로 연관 엔티티 조회 최적화
로그 분석 결과, member.getDepartment().getName() 호출 시마다 지연 로딩(Lazy Loading)으로 인한 추가 쿼리가 발생하고 있었다.
이를 Fetch Join을 사용하여 한 번의 쿼리로 데이터를 미리 가져오도록 수정했다.
@Query("SELECT m FROM Member m " +
"LEFT JOIN FETCH m.department " +
"LEFT JOIN FETCH m.college " +
"WHERE m.university.id = :universityId AND m.id != :memberId")
List<Member> findWithDetailsByUniversityIdAndIdNot(
@Param("universityId") Long universityId,
@Param("memberId") Long memberId
);테스트 결과
Fetch Join 적용 결과 — 연관 엔티티 조회를 한 번에 묶어 가져오면서, 루프 내부에서 반복되던 추가 조회가 줄어든 구간입니다.
| 메트릭 | 값 | 상태 | 설명 |
|---|---|---|---|
| 순수 로직 처리 시간 | 10 ~ 20 ms | 성공 | N+1 완전 해결 (IN 절 때 50~180ms보다 더 개선) |
| DB 조회 쿼리 | Fetch Join + IN절 | 성공 | Department 단건 조회 쿼리 사라짐 |
| 타임아웃 발생 여부 | 없음 (0건) | 해결 | 30초 대기 현상 사라짐 |
| p99 응답 시간 | ~15 sec | 경고 | 로직은 0.02초인데 응답이 15초 |
한계 발견
로직은 충분히 빨라졌는데, p99가 아직 15초인 이유를 분석했다.
// 문제의 코드 패턴
List<Member> allMembers = memberRepository.findWithDetailsByUniversityIdAndIdNot(...);
// ↑ 수천 명의 데이터를 전부 가져옴
List<Member> filtered = allMembers.stream()
.filter(member -> isFilterMatched(member, req)) // 메모리에서 필터링
.collect(toList());아무리 Fetch Join을 써서 쿼리 수를 줄여도, "수천 명의 데이터를 전부 DB에서 가져와(SELECT) 메모리에 올린 뒤 필터링(Stream filter)"하는 구조 자체가 문제였다.
특히 t2.micro의 1GB 메모리 환경에서 대량의 엔티티 객체를 생성하는 것은 GC 부하를 일으키고, 심할 경우 OOM(Out Of Memory) 발생 위험이 있었다. 따라서 필터링 로직을 DB 레벨(Where 절)로 완전히 내려야 했다.
[Phase 5] DB 레벨 필터링 및 Enum 적용
메모리 부하 줄이기
애플리케이션 메모리 부하를 줄이고, DB가 잘하는 필터링을 맡기자. 기존에는 수천 명의 데이터를 가져와 자바 메모리(Stream)에서 필터링했으나, 이를 DB의 WHERE 절로 이관하여 불필요한 데이터 전송과 메모리 사용을 차단했다.
| 구분 | 이전 (AS-IS) | 현재 (TO-BE) | 개선 효과 |
|---|---|---|---|
| 필터링 위치 | Java Memory (Stream filter) | Database (WHERE 절) | 데이터 전송량 감소, OOM 방지 |
| 관심사 필터 | m.getInterests() (Lazy Loading) | LEFT JOIN + 조건절 | N+1 반복 조회 제거 |
| 타입 안전성 | String (오타 위험) | Enum (InterestType) | 컴파일 타임 안전성 확보 |
결과
DB 레벨 필터링 및 Enum 적용 결과 — 애플리케이션 메모리에서 걸러내던 조건을 DB 조회 조건으로 옮긴 뒤, 불필요한 객체 생성과 후처리 비용이 줄어든 구간입니다.
| API | 평균 응답 시간 | 상태 |
|---|---|---|
추천 API (api_recommend) | 65ms | 성공 |
인기 API (api_popular) | 67ms | 성공 |
| API | 평균 응답 시간 | p95 | 원인 |
|---|---|---|---|
필터 API (api_filter) | 5,002ms | 9,376ms | 학번 필터링이 여전히 메모리에서 수행됨 |
추천/인기 API는 목표치에 도달했으나, 필터 API는 여전히 9초대로 느렸다. 원인은 학번(StudentNo) 필터링이었다.
문자열 파싱 로직(substring) 때문에 여전히 메모리 필터링을 수행하고 있었고, DISTINCT와 LEFT JOIN FETCH 조합으로 인해 임시 테이블 생성 및 정렬 부하가 발생하고 있었다.
[Final Phase] 커버링 인덱스와 Slice
남은 병목을 제거하기 위해 마지막 리팩토링을 진행했다.
- Repository JPQL 최적화 (LIKE & EXISTS)
- 메모리에서 하던 학번 필터링을
LIKE '2023%'쿼리로 이관했다. - 무거운
DISTINCT+JOIN FETCH를 제거하고, 가벼운EXISTS서브쿼리로 변경했다.
- Page → Slice 변경
- 무한 스크롤 방식이므로 전체 데이터 개수가 필요 없다. 매 요청마다 발생하는 무거운
COUNT(*)쿼리를 제거하기 위해Page대신Slice를 적용했다.
// 최종 Repository 코드
@Query("SELECT m FROM Member m " +
"WHERE m.status = 'ACTIVE' " +
"AND m.university.id = :universityId " +
"AND m.id != :memberId " +
// 동적 쿼리 조건들 (DB 레벨 필터링)
"AND (:collegeId IS NULL OR m.college.id = :collegeId) " +
"AND (:departmentId IS NULL OR m.department.id = :departmentId) " +
"AND (:studentNoPrefix IS NULL OR m.studentNo LIKE CONCAT(:studentNoPrefix, '%'))")
Slice<Member> findFilteredMembers(...); // Page -> Slice 변경- 커버링 인덱스(Covering Index) 추가
- 쿼리에 필요한 모든 컬럼을 포함하는 인덱스를 생성하여, 테이블 접근(Random I/O) 없이 인덱스 스캔만으로 데이터를 조회하도록 했다.
CREATE INDEX idx_member_filter_opt ON member(status, university_id, updated_at DESC);응답시간 백분위수(Percentile)의 의미
최종 결과를 해석하기 전에, p50/p95/p99의 의미를 짚고 넘어가자.
- p50 (median): 일반적인 사용자 경험. 절반의 요청이 이 시간 이내에 완료됨.
- p95: 20명 중 1명이 겪는 최악의 경험
- p99: 100명 중 1명의 극단적 케이스
평균 응답시간만 보면 함정에 빠질 수 있다. Long-tail distribution 때문에 평균은 좋아 보여도 일부 사용자는 극심한 지연을 겪을 수 있다. 그래서 SLO/SLA에서는 보통 p99를 기준으로 삼는다.
아래의 최종 결과Response Time Trend 지표에서 p50(녹색)과 p95(주황)의 차이가 작아진 것은 응답시간 분산이 줄었다는 의미다. 모든 사용자가 비슷하게 빠른 응답을 받게 된 것이다.
결과
| 지표 | Baseline | 최종 | 개선율 |
|---|---|---|---|
| 에러율 | 33.3% | 0.00% | 100% 개선 |
| p95 응답시간 | 30,001ms | 112ms | 268배 개선 |
| 처리량 | ~1 req/s | ~7 req/s | 7배 개선 |
번외: 커넥션 풀, 무조건 많으면 좋을까?
모든 튜닝이 끝난 후, 문득 궁금증이 생겼다. "DB 커넥션 개수(Pool Size)는 몇 개로 설정하는 게 가장 빠를까?"
보통 "많으면 많을수록 좋은 거 아니야?"라고 생각하기 쉽다. 그래서 직접 개수를 바꿔가며 실험해 보았다.
1. 실험 설계
쿼리 최적화가 완료된 상태에서 커넥션 개수만 다르게 설정하고 똑같은 부하를 주어보았다.
- 2개 (너무 적음): 문이 2개뿐인 상황
- 100개 (너무 많음): 문이 100개인 상황
- 5개 (이론상 추천): CPU 코어 수 기반
- 10개 (기존): 현재 설정값
실험 1: Pool Size = 2
실험 1. Pool Size = 2
- 결과: p95 1.64초
- 커넥션 수가 너무 적으면 DB가 처리할 수 있는 요청도 애플리케이션 앞단에서 대기하게 됩니다. 30 VUs가 동시에 들어오는 상황에서 커넥션이 2개뿐이면, 대부분의 요청은 쿼리를 실행하기 전부터 커넥션 획득을 기다립니다.
실험 2: Pool Size = 100
커넥션을 과하게 늘려도 빨라지지 않았습니다
| 케이스 | 총 요청 수 | p95 Latency |
|---|---|---|
| Pool=2 | 2,985 | 1.64s |
| Pool=100 | 2,095 (30% 감소) | 2.57s (56% 느림) |
이 결과는 커넥션을 많이 열어둔다고 항상 처리량이 좋아지는 것은 아니라는 점을 보여줍니다. 작은 DB 환경에서 동시에 너무 많은 작업이 들어오면 CPU는 실제 쿼리 처리보다 스레드 전환과 경합 비용에 더 많은 시간을 쓸 수 있습니다. 결국 Pool=100은 대기열을 줄이는 대신 Context Switching 비용을 키운 선택에 가까웠습니다.
실험 3: Pool Size = 5
HikariCP 공식은 출발점으로만 봤습니다
t2.micro(1 vCPU) 환경에서 공식만 적용하면 이론상 적정값은 3~5개에 가깝습니다. 그래서 Pool=5가 가장 안정적일 것이라고 예상했습니다. 하지만 실제 부하 테스트에서는 이론값만으로 설명하기 어려운 결과가 나왔습니다.
| Pool Size | 총 요청 수 | p95 Latency |
|---|---|---|
| Pool=5 | 2,502 | 2.17s |
| Pool=10 | ~7,500+ | 0.11s |
Pool=5는 Pool=10보다 느렸습니다.
이 차이는 공식이 틀렸다는 뜻이 아닙니다. 공식은 DB 서버 관점의 리소스 효율을 설명하는 데 가깝고, 이번 테스트에서는 애플리케이션 쪽 대기 시간이 더 크게 드러났습니다. 결국 이 값은 DB 효율과 요청 대기 시간 사이의 트레이드오프로 봐야 했습니다.
- 이론적 관점 (DB Server Side)
공식은 CPU가 Context Switching 없이 쉴 새 없이 일할 수 있는 한계치에 가깝습니다. 즉, DB 리소스 효율의 극대화가 목표입니다.
- 실제 서비스 관점 (Client Side)
동시 접속자(VU)가 30명일 때 커넥션이 5개라면, DB가 아무리 빨리 처리해도 나머지 요청은 애플리케이션 레벨에서 대기(Application Wait Time)해야 합니다.
이번 테스트 조건에서는 DB CPU 효율만 최적화하기보다, 애플리케이션에서 커넥션을 기다리는 시간을 줄이는 쪽이 응답 시간 개선에 더 유리했습니다. 그래서 Pool=10이 이 환경에서는 더 현실적인 균형점이었습니다.
결과 종합
Connection Pool 크기 비교 기준 — pool size는 크게 잡을수록 좋은 값이 아니라, 대기 시간과 context switching 사이에서 서비스 조건에 맞는 균형점을 찾는 값으로 봤습니다.

| Pool Size | 상태 | p95 Latency | 병목 원인 (Bottleneck) |
|---|---|---|---|
| 2 | 부족 (Under) | 1.64s | Wait Time |
| 처리량 대비 대기 시간이 큼 | |||
| 5 | 이론값 | 2.17s | Wait Time |
| 버퍼 부족으로 인한 대기열 발생 | |||
| 10 | 균형점 | 0.11s | 균형 |
| 대기열 해소와 리소스 효율의 균형 | |||
| 100 | 과다 (Over) | 2.57s | Context Switching |
| 과도한 스레드 경합으로 CPU 낭비 |
정리한 기준
- 커넥션은 많을수록 좋은 값이 아닙니다.
Pool=100은 대기열을 줄이는 대신 Context Switching 비용을 키웠습니다. - 공식은 출발점이지 결론이 아닙니다. 실제 트래픽 패턴, 인스턴스 크기, 목표 latency에 따라 적정값은 달라질 수 있습니다.
- 커넥션 풀 튜닝보다 쿼리 최적화가 먼저입니다. 쿼리가 커넥션을 오래 붙잡는 구조라면 pool size 조정은 증상을 늦출 뿐입니다.
timeout을 좁힐 때 남긴 확인 항목
이번 부하 테스트에서 가장 먼저 확인한 것은 “서버가 느리다”가 아니라 어느 자원이 먼저 포화되는가였습니다. 처음에는 응답 시간이 길고 timeout이 발생했지만, GC·CPU·스레드·커넥션 풀 지표를 나눠보니 병목은 쿼리 실행 방식과 커넥션 점유 시간으로 좁혀졌습니다.
이 테스트 뒤에 남긴 확인 항목은 다음과 같습니다.
- timeout은 가장 바깥의 증상이고, 먼저 봐야 할 것은 커넥션을 오래 붙잡은 작업입니다.
- pool size를 늘리면 대기열은 줄 수 있지만, 작은 인스턴스에서는 context switching 비용이 더 커질 수 있습니다.
@BatchSize는 Lazy Loading에는 도움이 되지만, 서비스 루프 안의 Repository 직접 호출에는 개입하지 못합니다.- 한 API의 순수 로직 시간이 줄어도, 다른 느린 API가 공유 커넥션 풀을 점유하면 전체 응답 시간은 계속 밀릴 수 있습니다.
- 부하 테스트 수치는 평균보다 p95, timeout, connection acquire time, waiting thread를 함께 봐야 합니다.
성능 개선은 한 번의 설정 변경으로 끝나지 않았습니다. 인덱스를 추가해도 커넥션 경합이 남았고, @BatchSize를 적용해도 Repository 직접 호출 구조에서는 효과가 제한적이었습니다. 결국 루프 안의 DB 왕복을 줄이고, 느린 API가 공유 커넥션 풀을 점유하는 문제를 함께 정리해야 했습니다. 평균 응답 시간보다 더 먼저 본 것은 timeout이 시작되는 지점과 p95 구간이 어디서 밀리는지였습니다.
이 테스트에서 k6는 “얼마나 빨라졌는지”를 포장하는 도구가 아니었습니다. 어떤 가설이 틀렸는지 지우는 도구에 더 가까웠습니다. pool size만 늘리는 접근, 인덱스만 추가하는 접근, @BatchSize만 기대하는 접근이 각각 어디까지 효과가 있고 어디서 멈추는지 확인했습니다. 마지막에 남은 수치는 성과표라기보다, 병목이 DB 왕복과 커넥션 점유로 좁혀졌다는 검증 기록에 가깝습니다.