채팅 알림은 메시지 저장 뒤에 따라오는 부수 효과처럼 보이지만, 실제 운영에서는 사용자가 가장 먼저 체감하는 기능이었습니다. CATXI에서도 처음 보인 증상은 단순했습니다. 채팅 메시지는 저장됐는데 푸시가 가지 않거나, 같은 알림이 두 번 도착하는 경우가 있었습니다.
문제는 FCM 하나가 아니었습니다. 채팅 저장, 알림 발행, 소비, 외부 호출 사이마다 상태가 사라질 수 있는 경계가 있었고, 장애 이후에는 어디까지 처리됐고 어디서 멈췄는지를 바로 설명하기 어려웠습니다.
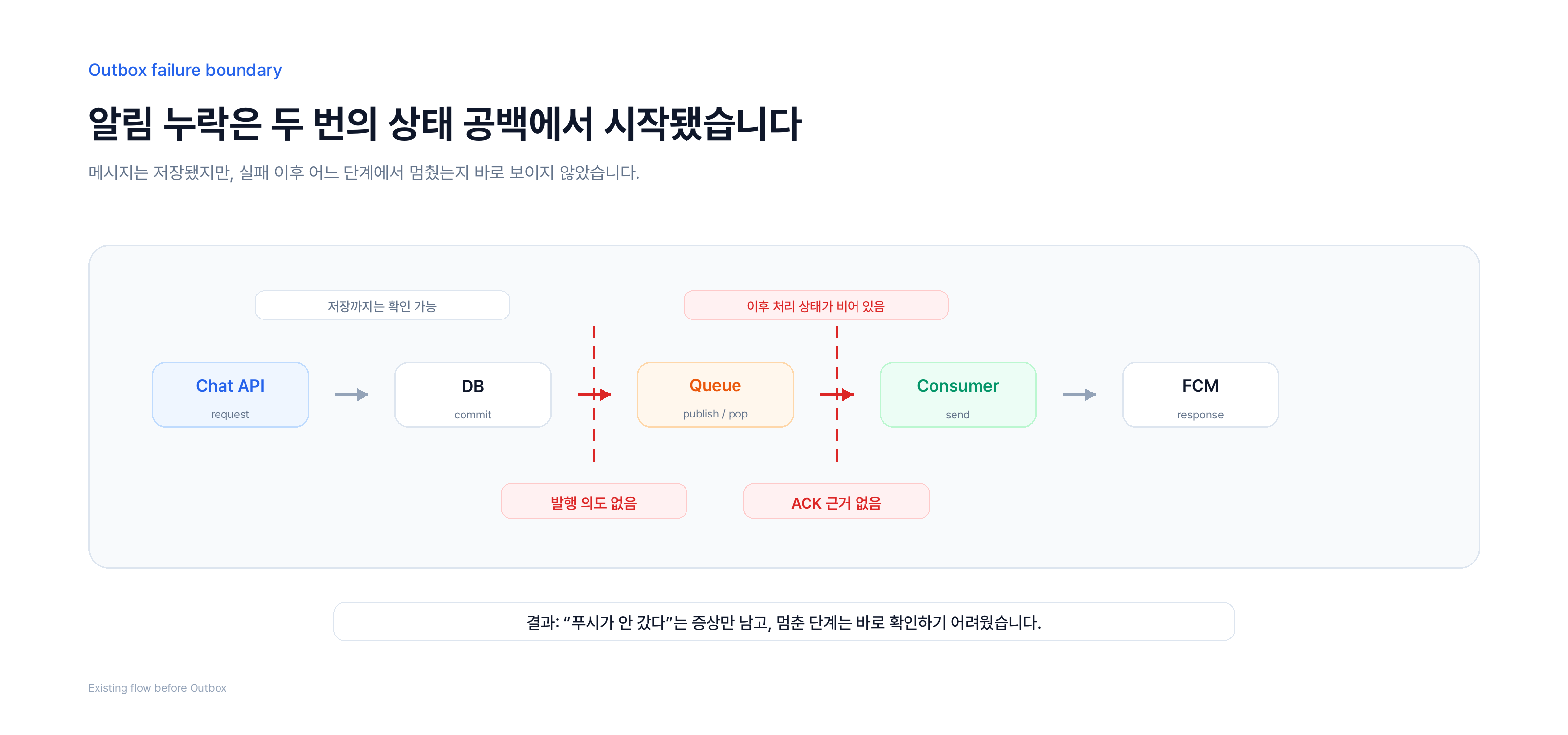
따라서 초점은 Redis 자료구조 비교가 아니었습니다. 푸시 알림을 사용자 경험에 직접 닿는 비동기 작업으로 보고, 저장·발행·소비·재처리 경계를 어떻게 나눴는지 정리하는 쪽에 가까웠습니다. 핵심은 더 빠른 큐를 고르는 것이 아니라, 실패가 발생했을 때 발행 의도와 처리 상태가 시스템 안에 남는 구조를 만드는 것이었습니다.
먼저 실패 모델을 좁혔습니다
알림 문제는 한 문장으로 말하면 “푸시가 안 갔다”입니다. 하지만 운영자가 실제로 확인해야 하는 질문은 더 잘게 나뉩니다.
- 채팅 메시지는 저장됐는가?
- 알림을 보내야 한다는 의도는 남았는가?
- 이벤트가 큐에 들어갔는가?
- 어떤 consumer가 읽었는가?
- FCM 호출은 성공했는가?
- ACK 전에 consumer가 죽었는가?
- 같은 이벤트가 재시도되었을 때 중복 발송을 통제할 수 있는가?
이 질문들을 시간순으로 다시 나누면 알림 파이프라인은 하나의 큐 문제가 아니라 여러 개의 실패 경계로 보였습니다. 저장 단계에서는 “알림을 보내야 했다는 사실”이 남아야 했고, 전달 단계에서는 “어떤 consumer가 어디까지 처리했는지”가 남아야 했습니다. 외부 FCM 호출은 그 다음 문제였습니다. 서버가 통제할 수 있는 경계와 외부 인프라에 맡길 수밖에 없는 경계를 나누지 않으면, 같은 알림 누락도 매번 다른 원인처럼 보였습니다.
| 구간 | 확인해야 할 질문 | 상태로 남겨야 하는 것 |
|---|---|---|
| 저장 | 채팅 메시지는 커밋됐는가? | 메시지 row와 같은 트랜잭션 안의 발행 의도 |
| 발행 | 알림 이벤트가 큐로 이동했는가? | outbox 상태와 stream message id |
| 소비 | consumer가 읽고 ACK했는가? | pending 상태, idle time, retry count |
| 외부 호출 | FCM 요청은 어떤 결과를 받았는가? | event id와 연결된 응답 코드, 오류 유형 |
이 질문에 답하지 못하면 장애 대응은 로그 추정에 가까워집니다. 반대로 각 단계가 상태로 남아 있으면, 알림 누락은 “사라진 사건”이 아니라 어느 단계에 머문 작업인지 확인 가능한 사건이 됩니다.
이 기준을 먼저 세우지 않으면 기술 선택이 쉽게 흐려집니다. Pub/Sub, List, Streams, Kafka 같은 이름은 모두 메시지를 다루는 도구처럼 보이지만, 각 도구가 보장하는 실패 모델은 다릅니다. 알림 파이프라인에서는 “빨리 전달되는가”보다 “읽힌 뒤 실패했을 때 다시 찾을 수 있는가”가 더 중요했습니다.
Pub/Sub은 전파에는 맞았지만 작업 처리에는 맞지 않았습니다
초기 구조는 Redis Pub/Sub에 가까웠습니다. 채팅 메시지를 저장한 뒤 알림 이벤트를 발행하고, 각 서버가 이를 구독해 FCM을 호출했습니다. 단일 서버에서는 이 구조가 단순하고 빠르게 보입니다. 메시지가 발생하면 즉시 구독자에게 전달되고, 구현해야 할 상태도 많지 않습니다.
문제는 서버가 여러 대가 되는 순간 드러났습니다. Pub/Sub은 기본적으로 브로드캐스트 모델입니다. 하나의 이벤트가 발생하면 모든 subscriber가 같은 이벤트를 받습니다. 실시간 채팅 전파처럼 여러 서버가 동시에 같은 이벤트를 알아야 하는 경우에는 자연스럽습니다. 하지만 푸시 알림처럼 하나의 작업을 단 하나의 consumer만 처리해야 하는 경우에는 모델 자체가 맞지 않습니다.
운영에서 보인 중복 발송은 이 구조에서 충분히 발생할 수 있는 결과였습니다. 서버가 두 대면 두 대가 같은 알림을 보낼 수 있고, 인스턴스 수가 늘어나면 중복 가능성도 같이 커집니다. 이것은 단순한 버그라기보다 broadcast를 work queue처럼 사용한 설계 문제에 가까웠습니다.
복구 관점에서도 Pub/Sub은 한계가 분명했습니다. 구독자가 없는 순간에 발행된 이벤트는 나중에 다시 읽을 수 없습니다. 배포 중 인스턴스가 재시작되거나 consumer가 잠시 비어 있는 시간대에 발행된 이벤트는 시스템 안에 남지 않았습니다. 장애가 유실로 이어지고, 그 유실을 다시 설명할 근거도 남지 않는 구조였습니다.
List Queue는 중복을 줄였지만 ACK 경계가 없었습니다
다음 단계에서는 Redis List를 queue처럼 사용했습니다. LPUSH와 BRPOP 조합을 사용하면 여러 서버가 동시에 대기하더라도 메시지를 가져가는 consumer는 하나뿐입니다. 이 구조는 Pub/Sub에서 보이던 중복 발송 문제를 줄이는 데는 도움이 됐습니다.
하지만 List Queue에도 중요한 경계가 빠져 있었습니다. BRPOP은 메시지를 반환하는 순간 큐에서 제거합니다. consumer가 메시지를 받은 직후 FCM을 호출하기 전에 죽으면, 메시지는 이미 큐에서 사라진 상태입니다. 즉, 중복은 줄었지만 소비 중 장애가 곧 유실로 이어질 수 있었습니다.
더 근본적인 문제는 채팅 저장과 알림 이벤트 생성이 서로 다른 실패 경계에 있었다는 점입니다. 채팅 저장은 MySQL 트랜잭션 안에서 일어나지만, Redis 발행은 그 바깥의 별도 작업입니다. 따라서 DB 저장은 성공했는데 Redis 발행이 실패하거나, 발행 직전 프로세스가 종료되는 상황이 남을 수 있었습니다.
이 상태에서는 사용자 제보가 들어와도 확인이 어렵습니다. 채팅 메시지는 보이지만 알림 이벤트가 애초에 만들어졌는지, 만들어졌지만 소비 중 사라졌는지, FCM 호출에서 실패했는지 구분하기 어렵기 때문입니다. 그래서 문제를 큐 하나로 보지 않고 생성 단계와 전달 단계로 나누기로 했습니다.
| 구조 | 잘 맞는 문제 | 알림 파이프라인에서의 한계 |
|---|---|---|
| Redis Pub/Sub | 여러 구독자에게 같은 이벤트를 빠르게 전파 | 모든 subscriber가 같은 알림을 처리할 수 있고, 구독자가 없던 시점의 이벤트는 남지 않습니다. |
| Redis List Queue | 여러 consumer 중 하나가 작업을 가져가는 경쟁 소비 | BRPOP 이후 consumer가 죽으면 메시지가 이미 큐에서 제거되어 재처리 근거가 사라질 수 있습니다. |
| Outbox + Redis Streams | 발행 의도 저장, consumer group 처리, ACK 전 실패 추적 | outbox table, poller, pending 관리, DLQ 같은 운영 포인트가 추가됩니다. |
Outbox와 Streams는 서로 다른 실패 경계를 닫습니다

최종 구조에서는 Transactional Outbox와 Redis Streams를 함께 사용했습니다. 두 기술을 같이 쓴 이유는 각각 닫는 실패 경계가 다르기 때문입니다.
여기서는 큐 이름보다 상태가 남는 지점을 더 크게 봤습니다. DB 트랜잭션에는 “보내야 했다는 의도”가 남아야 하고, Streams에는 “어느 consumer가 읽었고 ACK 전 어디에 멈췄는지”가 남아야 했습니다. FCM 응답은 그 다음 경계입니다. 이 순서를 나눠야 알림 누락을 막연한 장애가 아니라, 특정 단계에 머문 작업으로 좁혀볼 수 있습니다.
- Outbox는 채팅 저장과 알림 발행 의도를 같은 DB 트랜잭션 안에 묶습니다.
- Redis Streams는 발행된 이벤트가 consumer에게 읽힌 뒤 ACK될 때까지 처리 상태를 추적합니다.
Outbox만 있으면 발행 의도는 남지만, consumer 처리 중 장애를 메시지 브로커 수준에서 다루기 어렵습니다. Streams만 쓰면 consumer group과 pending list는 얻지만, DB 저장과 Redis 발행 사이의 원자성 문제는 남습니다. 둘을 함께 둔 이유는 이 두 경계를 모두 분리해서 보기 위해서였습니다.
선택하지 않은 대안도 있었습니다
이 구조를 정하기 전에 단순한 선택지도 있었습니다. Redis Streams만 사용하면 consumer group과 pending 관리는 얻을 수 있지만, 채팅 저장과 이벤트 발행 사이의 실패는 여전히 설명하기 어렵습니다. 반대로 DB outbox만 두고 consumer가 DB를 직접 polling하도록 만들면 발행 의도는 남지만, 메시지가 여러 consumer 사이에서 어떤 상태로 이동했는지 추적하는 책임을 애플리케이션이 더 많이 떠안게 됩니다.
Kafka 같은 별도 메시지 브로커도 선택지가 될 수 있습니다. 다만 이 문제에서 먼저 필요했던 것은 대규모 스트리밍 플랫폼이 아니라, 이미 운영 중인 Redis 기반 인프라 안에서 누락 의심 건을 재현 가능한 상태로 남기는 것이었습니다. 그래서 새 인프라를 늘리기보다, MySQL 트랜잭션 경계에는 outbox를 두고 소비 상태에는 Redis Streams를 두는 쪽이 이 시점의 운영 비용과 복구 가능성 사이에서 더 맞았습니다.
이 판단은 “Redis Streams가 Kafka보다 낫다”는 결론이 아닙니다. 요구한 보장은 더 단순했습니다. 채팅 저장과 알림 발행 의도가 함께 남고, consumer가 죽었을 때 메시지가 pending 상태로 다시 보이며, 반복 실패를 DLQ로 분리할 수 있으면 됐습니다. 기술 선택은 이 실패 모델을 만족하는 가장 작은 변경 범위에서 결정했습니다.
Transactional Outbox로 발행 의도를 먼저 고정했습니다
먼저 바꾼 것은 Redis 발행 위치였습니다. 채팅을 저장한 뒤 곧바로 Redis에 push하는 대신, 같은 MySQL 트랜잭션 안에서 outbox row를 함께 저장했습니다. 이렇게 하면 채팅 메시지가 저장된 경우 알림을 보내야 한다는 의도도 DB 안에 남습니다. 반대로 outbox 저장에 실패하면 채팅 저장도 함께 롤백됩니다.
@Transactional
public void saveMessage(ChatMessage message) {
ChatMessage saved = chatMessageRepository.save(message);
PushOutboxEvent outbox = PushOutboxEvent.builder()
.eventId(UUID.randomUUID().toString())
.messageId(saved.getId())
.eventType(PushEventType.CHAT_MESSAGE)
.payload(objectMapper.writeValueAsString(toPushPayload(saved)))
.status(OutboxStatus.PENDING)
.createdAt(Instant.now())
.build();
pushOutboxRepository.save(outbox);
}여기서 outbox는 queue 자체가 아닙니다. 더 정확히는 보내야 했다는 근거를 DB에 남기는 장치입니다. poller는 PENDING 상태의 row를 읽어 Redis Streams에 발행하고, 발행 요청이 성공하면 상태를 SENT로 바꿉니다. 이 구조에서는 Redis 발행이 잠시 실패해도 outbox row를 기준으로 다시 시도할 수 있습니다.
다만 이 경계에도 반례는 남습니다. Redis Streams 발행은 성공했지만 outbox 상태를 SENT로 바꾸기 전에 poller가 죽으면, 같은 outbox row가 다시 발행될 수 있습니다. 그래서 이 구조는 “정확히 한 번 발행”이 아니라, 발행 의도를 잃지 않고 중복 가능성을 event id로 추적하는 구조로 봐야 했습니다.
이 방식이 모든 실패를 없애지는 않습니다. 대신 실패가 발생했을 때 기준점이 생깁니다. 예전에는 “채팅은 있는데 알림은 왜 없지?”에서 시작했다면, 이제는 “outbox row가 있는가, Streams에 발행됐는가, consumer가 ACK했는가”로 좁혀갈 수 있습니다.
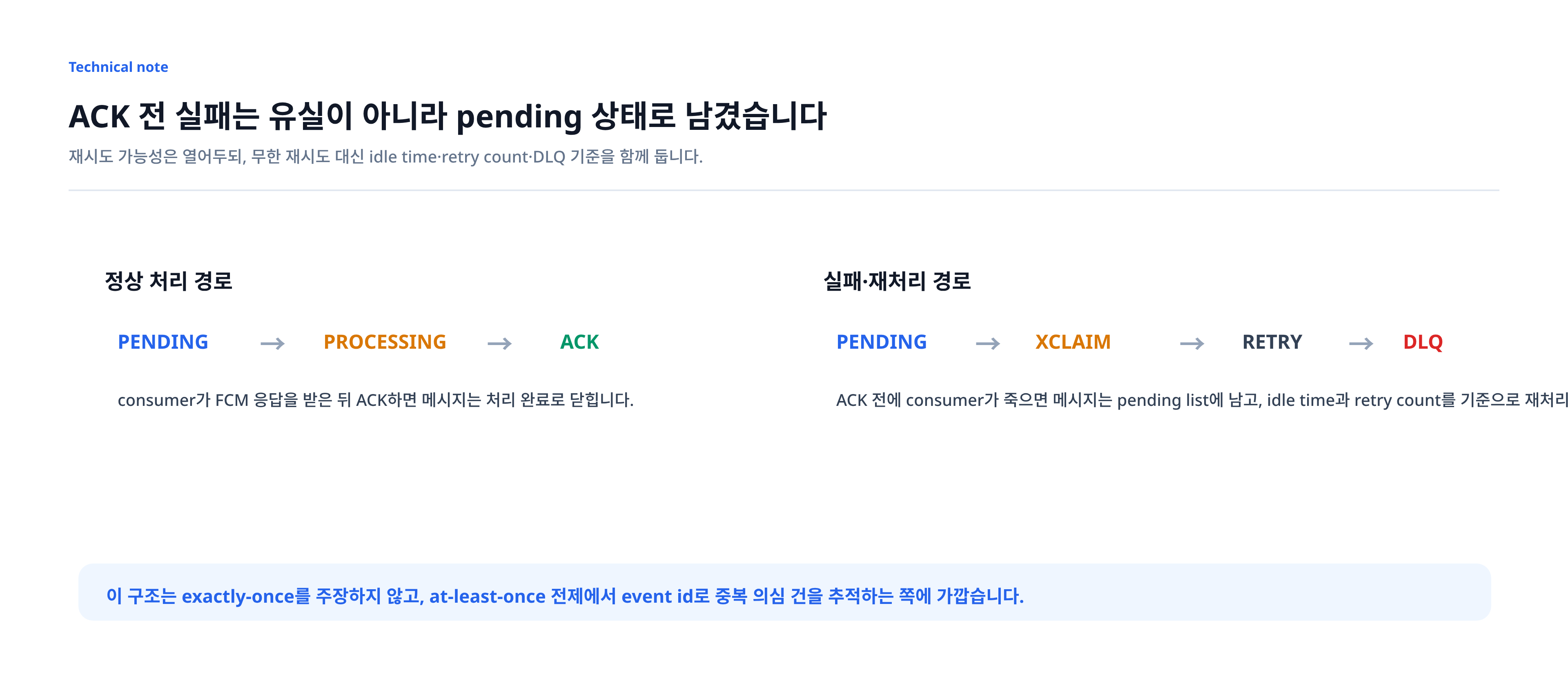
Redis Streams는 소비 중 실패를 상태로 남깁니다
Redis Streams를 선택한 이유는 Consumer Group과 ACK 경계 때문이었습니다. consumer가 메시지를 읽었다고 해서 바로 사라지는 것이 아니라, 처리 완료 후 ACK하기 전까지 pending 상태로 남습니다. 이 차이가 List Queue와 가장 크게 달랐습니다.
처리 흐름은 다음과 같습니다.
1. poller가 outbox PENDING row를 읽는다.
2. Redis Streams에 event를 publish한다.
3. publish 성공 시 outbox status를 SENT로 바꾼다.
4. consumer group이 stream message를 읽는다.
5. FCM send 성공 시 ACK 한다.
6. consumer crash 또는 timeout이면 message는 pending list에 남는다.
7. idle timeout 이후 다른 consumer가 XCLAIM으로 소유권을 가져간다.
8. retry count 초과 시 DLQ로 분리하고 원본 메시지는 ACK 한다.이 구조의 핵심은 장애가 유실이 아니라 상태 전이로 보인다는 점입니다. consumer가 FCM 호출 직전에 죽어도 메시지는 pending list에 남습니다. 다른 consumer가 일정 idle time 이후 XCLAIM으로 가져와 재처리할 수 있고, 반복 실패는 DLQ로 분리할 수 있습니다.
다만 이 구조를 exactly-once로 설명하지는 않았습니다. FCM 호출 직후 ACK 전에 consumer가 죽는다면 같은 event id가 다시 처리될 수 있습니다. 그래서 설계의 중심은 “중복이 절대 없다”가 아니라, at-least-once 전제에서 중복 의심 건을 추적하고 재시도 범위를 통제하는 것이었습니다.
재시도는 무한정 하지 않았습니다
재처리 가능하다는 사실만으로 운영 안정성이 생기지는 않습니다. 오히려 재시도 기준이 없으면 장애를 더 키울 수 있습니다. FCM 일시 오류처럼 다시 보내면 성공할 수 있는 경우도 있지만, 만료된 디바이스 토큰처럼 반복해도 성공하지 않는 경우도 있습니다.
그래서 실패를 세 가지로 나눠 봤습니다.
| 실패 유형 | 예시 | 처리 기준 |
|---|---|---|
| 일시 실패 | 네트워크 지연, FCM 일시 오류 | pending 상태로 남기고 제한된 횟수 안에서 재시도합니다. |
| 반복 실패 | 같은 오류가 재시도 횟수 이상 반복 | DLQ로 분리하고 원본 메시지는 ACK해 파이프라인 정체를 막습니다. |
| 처리 불가 실패 | 유효하지 않은 디바이스 토큰, 잘못된 payload | 자동 재시도보다 별도 확인 대상으로 남깁니다. |
이 기준을 두면 실패 메시지 하나가 전체 파이프라인을 막지 않습니다. 동시에 실패가 조용히 사라지지도 않습니다. 운영자는 DLQ에 쌓인 메시지를 기준으로 오류 유형을 확인하고, 특정 오류 코드가 반복되는지 볼 수 있습니다.
Consumer는 at-least-once를 전제로 작성해야 합니다
Outbox와 Redis Streams를 사용하면 재처리 근거가 생깁니다. 하지만 이 말은 같은 이벤트가 두 번 처리될 수 있다는 뜻이기도 합니다. ACK 직전에 consumer가 죽으면 FCM 발송은 이미 시도됐지만 Redis 입장에서는 아직 ACK되지 않은 메시지로 남을 수 있습니다. 이후 다른 consumer가 다시 처리하면 중복 발송 가능성이 생깁니다.
따라서 이 구조를 “정확히 한 번 처리”로 설명하면 위험합니다. 더 정확한 표현은 at-least-once 처리 모델을 받아들이고, 중복 가능성을 이벤트 식별자로 통제하는 구조입니다.
이벤트 식별자는 outbox row가 생성될 때 만들어지고, Streams payload와 FCM 발송 로그, ACK, DLQ까지 같은 기준으로 이어져야 합니다. 그래야 중복 발송이 의심될 때 “같은 이벤트가 재처리된 것인지”, “서로 다른 메시지가 비슷하게 보인 것인지”를 구분할 수 있습니다.
이 기준은 운영에서도 중요했습니다. 푸시 알림은 외부 FCM 응답과 디바이스 수신까지 포함하면 완전한 exactly-once를 보장하기 어렵습니다. 그래서 서버 내부에서 통제할 수 있는 범위를 명확히 잡았습니다. 발행 의도는 outbox로 남기고, 소비 상태는 Streams로 남기며, 외부 발송 결과는 event id로 연결해 확인할 수 있게 했습니다.
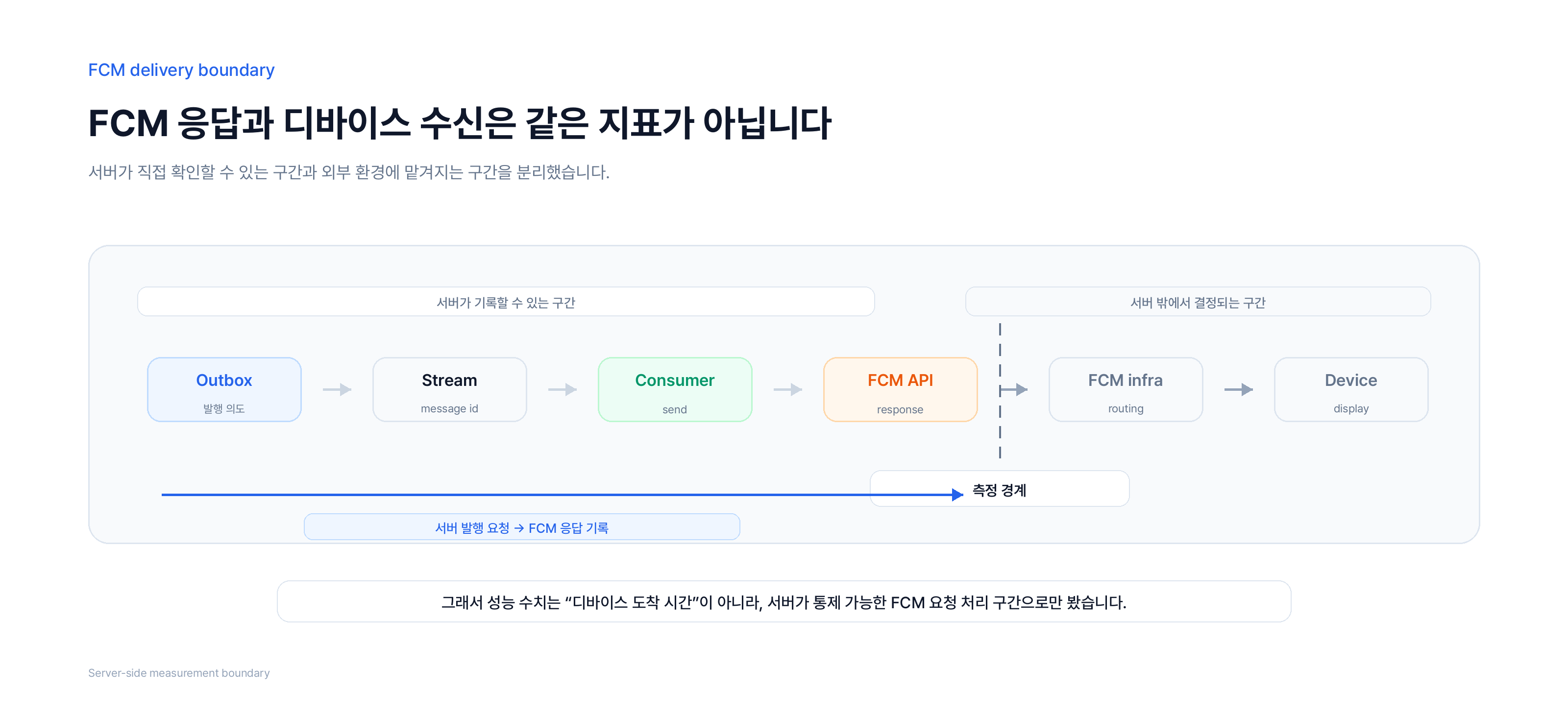
FCM 응답은 디바이스 수신과 분리해서 봤습니다
FCM을 붙이면 알림 파이프라인이 끝난 것처럼 보이지만, 서버 입장에서 실제로 확인할 수 있는 경계는 더 좁습니다. 서버는 FCM API를 호출하고 응답을 기록할 수 있습니다. 하지만 그 이후의 라우팅, OS 알림 정책, 앱의 백그라운드 상태, 네트워크 환경, 사용자의 알림 허용 여부까지 직접 보장할 수는 없습니다.
그래서 이 글에서는 FCM을 “최종 도착 보장 장치”가 아니라 서버가 외부 푸시 인프라에 전달을 요청하는 경계로 봤습니다. 이 기준을 먼저 세우지 않으면, 서버 안에서 해결할 수 있는 지연과 디바이스 환경 때문에 발생하는 미수신을 같은 문제로 섞게 됩니다.
| 구간 | 서버가 할 수 있는 일 | 서버가 직접 보장하기 어려운 일 |
|---|---|---|
| FCM API 호출 전 | event id, payload, 대상 토큰, 재시도 횟수를 기록합니다. | 없습니다. 이 구간은 서버 내부 상태로 추적할 수 있습니다. |
| FCM API 응답 | 응답 코드와 오류 유형을 event id와 연결해 남깁니다. | 응답 이후 실제 디바이스 표시까지의 시간은 알 수 없습니다. |
| 디바이스 수신 | 사용자 제보나 클라이언트 로그가 있을 때 서버 로그와 대조합니다. | OS 정책, 앱 상태, 네트워크, 알림 권한은 서버가 통제하지 못합니다. |
이 구분은 운영 지표를 정할 때 중요했습니다. 500ms에서 80ms로 줄었다고 표현한 구간은 디바이스에 알림이 표시되기까지의 시간이 아닙니다. 서버 발행 요청부터 FCM 응답을 기록하기까지의 처리 구간입니다. 범위를 이렇게 좁혀야 수치가 과장되지 않고, 알림 지연과 알림 누락을 분리해서 볼 수 있습니다. 같은 숫자라도 consumer 수, payload 크기, 외부 API 상태가 달라지면 비교 의미가 약해지기 때문에, 이 글에서는 서버 내부에서 통제할 수 있는 구간만 성과로 남겼습니다.
또 하나의 기준은 오류 처리였습니다. FCM 응답이 실패라고 해서 모두 같은 재시도 대상은 아니었습니다. 일시적인 네트워크 오류나 FCM 서버 오류는 제한된 횟수 안에서 재시도할 수 있지만, 유효하지 않은 디바이스 토큰처럼 반복해도 성공하기 어려운 오류는 별도 상태로 분리해야 했습니다. 그래야 실패 메시지 하나가 계속 재시도되며 전체 파이프라인을 밀어내지 않습니다.
운영 지표는 큐 길이보다 상태 전이를 먼저 봤습니다
비동기 파이프라인에서 큐 길이만 보는 것은 충분하지 않습니다. 큐 길이가 짧아도 pending에 오래 머무는 메시지가 있을 수 있고, 큐 길이가 길어도 consumer가 정상적으로 따라잡는 중이면 장애가 아닐 수 있습니다. 그래서 관측 기준을 queue depth 하나로 두지 않았습니다.
운영에서 유용했던 지표는 다음에 가까웠습니다.
- outbox
PENDINGrow의 age - Redis Streams
Pending메시지의 idle time - consumer별 처리량과 ACK까지 걸린 시간
XCLAIM발생량과 재처리 성공 여부- DLQ로 이동한 메시지 수와 오류 코드 분포
- 서버 발행 요청부터 FCM 응답 기록까지의 처리 시간
이 지표들은 “알림이 느리다”에서 멈추지 않게 해 줍니다. 생성 단계가 밀리는지, Streams 소비가 밀리는지, FCM 호출에서 실패하는지, 특정 consumer가 불안정한지 나눠볼 수 있습니다. 알림 파이프라인에서는 빠른 평균 지연 시간만 보는 대신, 실패가 어느 단계에 머무는지 설명할 수 있어야 합니다.
운영 대응 방식도 달라졌습니다
운영에서는 사용자 제보와 시스템 상태를 같은 기준으로 맞추는 것이 중요했습니다. 이전에는 사용자가 “알림이 오지 않았다”고 말하면 분산된 로그를 따라가며 추정해야 했습니다. 메시지는 저장됐는지, Redis에는 발행됐는지, consumer가 읽었는지, FCM 호출이 있었는지를 순서대로 맞춰 봐야 했고, 이 과정은 오래 걸렸습니다.
전환 이후에는 확인 순서가 훨씬 명확해졌습니다.
- 메시지 ID로 outbox row가 있는지 확인합니다.
- outbox 상태가
PENDING,SENT,FAILED중 어디에 있는지 확인합니다. - Streams pending list에서 해당 event id가 남아 있는지 확인합니다.
- ACK 여부와 FCM 응답 로그를 같은 event id로 대조합니다.
- 반복 실패라면 DLQ와 마지막 오류를 확인합니다.
실제 운영 로그 기준으로 월 5~7건 수준의 알림 누락 의심 패턴을 이 흐름으로 다시 확인할 수 있게 됐고, 이전에는 약 20분 걸리던 의심 건 확인을 XPENDING과 outbox 상태 대조로 2분 이내에 좁힐 수 있었습니다. 여기서 측정한 지연은 디바이스 표시 시간이 아니라 서버 발행 요청부터 FCM 응답 기록까지의 처리 구간입니다. 같은 기준으로 본 이 구간은 500ms 수준에서 80ms 수준으로 낮아졌습니다.
숫자보다 더 크게 달라진 부분은 대응 방식이었습니다. 이전에는 알림 실패가 재현하기 어려운 사건에 가까웠지만, 이후에는 발행 의도, 소비 상태, FCM 응답을 같은 event id로 따라갈 수 있는 운영 절차가 생겼습니다.
이 구조의 비용도 명확했습니다
Outbox와 Redis Streams가 항상 가장 단순한 답은 아닙니다. 이 구조는 분명한 운영 비용을 만듭니다.
| 추가 비용 | 왜 필요한가 |
|---|---|
| outbox table 관리 | 발행 의도를 DB 트랜잭션 안에 남기기 위해 필요합니다. |
| poller 운영 | DB에 남은 발행 의도를 Redis Streams로 옮기는 경계가 필요합니다. |
| pending, XCLAIM, DLQ 관리 | 소비 중 실패를 재처리 가능한 상태로 남기기 위해 필요합니다. |
| 멱등성 기준 | 재처리 과정에서 같은 이벤트가 다시 처리될 가능성을 통제하기 위해 필요합니다. |
이 비용을 감수한 이유는 채팅 알림이 “가끔 빠져도 괜찮은 이벤트”가 아니었기 때문입니다. 메시지가 저장되어 있어도 알림이 오지 않으면 사용자는 대화가 끊겼다고 느낍니다. 단순하지만 상태가 남지 않는 구조보다, 조금 더 복잡하더라도 실패가 추적 가능한 구조가 운영에서는 더 다루기 쉬웠습니다.
알림 실패를 따라가는 순서
이 개선에서 Redis 자료구조를 바꾼 일보다 더 중요했던 것은 푸시 알림을 어떤 종류의 작업으로 볼지 다시 정한 점이었습니다. 알림은 빠르게 흘려보내는 이벤트처럼 보이지만, 채팅 맥락에서는 저장된 메시지와 사용자 인지가 연결되는 작업입니다. 발행 의도, 소비 상태, 외부 응답이 남지 않으면 실패가 발생했을 때 원인을 다시 좁히기 어렵습니다.
Pub/Sub은 빠른 전파에는 적합했지만 하나의 작업을 한 consumer만 처리해야 하는 알림에는 맞지 않았습니다. List Queue는 중복을 줄였지만 ACK 전 장애를 복구할 근거가 부족했습니다. Outbox와 Redis Streams를 함께 둔 이유는 이 두 실패 경계를 나눠 보기 위해서였습니다.
이후 알림 실패를 볼 때는 “FCM이 문제인가?”로 바로 뛰지 않습니다. 먼저 outbox에 발행 의도가 남았는지, Streams에 들어갔는지, pending에 멈춰 있는지, ACK 이후 외부 응답이 어떤지 순서대로 봅니다. 이 순서가 생기면서 중복 발송, 소비 중 유실, 발행 의도 누락을 같은 파이프라인 안에서 설명할 수 있게 됐습니다. Outbox와 Redis Streams를 둔 이유도 완전한 성공을 보장하기 위해서가 아니라, 실패를 다시 찾을 수 있는 흔적을 남기기 위해서였습니다.