분산 락을 점검할 때 가장 먼저 보이는 지표는 보통 대기 시간과 처리량입니다. 락을 잡는 데 얼마나 걸리는지, 경합이 생겼을 때 요청이 얼마나 밀리는지, Redis 호출이 얼마나 늘어나는지가 먼저 눈에 들어옵니다.
하지만 이 작업에서 더 위험했던 실패는 성능 지표 뒤쪽에 있었습니다. 락을 못 잡아 요청이 실패한 것이 아니라, 이미 끝났다고 생각한 이전 실행 흐름이 지금 실행 중인 다른 요청의 락을 지우는 문제였습니다. 이 경우 실패는 요청 하나에서 끝나지 않습니다. 동시에 하나만 실행되어야 하는 임계 구역이 열리고, 서로 겹치면 안 되는 작업이 같은 자원 위에서 동시에 진행될 수 있습니다.
당시 custom Redis spin lock은 이런 반례를 품고 있었습니다. 크레딧 차감, quota 등록, 배치 정리처럼 한 번에 하나만 실행되어야 하는 경로에서 TTL 만료와 재획득이 겹치면, 먼저 시작한 요청이 뒤에 락을 잡은 요청의 락을 해제할 수 있었습니다. 겉으로 보면 드문 race condition입니다. 하지만 분산 락에서 이런 반례는 빈도보다 의미가 더 큽니다. 한 번이라도 재현되면 lock이 보호한다고 믿었던 경계 자체를 다시 의심해야 하기 때문입니다.
이번 작업은 Redis를 통째로 다시 설계한 이야기가 아닙니다. cache, session, streams, Pub/Sub까지 모두 옮긴 migration이 아니라, correctness가 실제로 깨질 수 있었던 lock path만 좁게 떼어내 복구한 작업에 가깝습니다. 문제는 Redis 전체가 아니라 lock contract의 문제였고, 그래서 수정 범위도 lock contract를 검증할 수 있는 범위로 제한했습니다.
먼저 실패 모델을 하나로 좁혔습니다
분산 락 문제가 생기면 여러 현상이 한꺼번에 보입니다. 중복 실행, timeout, Redis key 잔존, 수동 복구, 느린 대기 시간이 모두 같은 문제처럼 보일 수 있습니다. 하지만 이 상태에서 바로 라이브러리를 바꾸면 수정 범위가 흐려집니다. 그래서 먼저 실제로 막아야 할 실패 모델을 하나로 좁혔습니다.
이번 작업의 핵심 실패 모델은 소유자 검증 없는 unlock이었습니다.
여기서 먼저 정리한 것은 증상과 원인을 분리하는 일이었습니다. 운영 화면에서는 중복 실행, 긴 대기 시간, 수동 복구가 한꺼번에 보일 수 있지만, 모두 같은 층위의 문제가 아니었습니다. 이번 글에서 중심으로 다룬 것은 “락을 얻지 못했다”가 아니라 “이전 실행 흐름이 현재 owner의 락을 지울 수 있었다”는 계약 위반입니다.
| 구분 | 이번 글에서의 위치 | 확인 기준 |
|---|---|---|
| 소유자 없는 unlock | 핵심 실패 모델 | 현재 owner가 아닌 흐름이 unlock을 호출했을 때 lock key가 삭제되는지 |
| TTL 만료 후 재획득 | 실패를 드러내는 조건 | 작업 시간이 lease보다 길어졌을 때 임계 구역이 다시 열리는지 |
| polling 기반 대기 | 운영 비용을 키우는 보조 리스크 | 경합 시 Redis 재시도와 대기 시간이 과도하게 늘어나는지 |
- Thread A가 락을 잡습니다.
- 작업이 예상보다 오래 걸려 TTL이 먼저 만료됩니다.
- Thread B가 같은 key로 락을 다시 잡습니다.
- Thread A가 뒤늦게
unlock()을 호출합니다. - Thread B가 가진 락이 삭제됩니다.
이 실패에서 중요한 점은 A가 자기 락을 해제한 것이 아니라는 점입니다. A는 자신이 처음 잡았던 락을 해제한다고 생각하지만, 실제 Redis key에는 이미 B가 잡은 새 락이 들어 있습니다. 해제 시점에 owner를 확인하지 않으면 A의 cleanup 코드가 B의 임계 구역을 열어버립니다.
TTL 만료로 인한 중복 실행 가능성은 이 실패를 드러나게 만든 조건이었고, polling 기반 대기는 같은 구현에서 함께 보인 운영 리스크였습니다. 세 문제는 같은 코드에서 관측됐지만 원인은 달랐습니다. 그래서 검증도 하나로 뭉치지 않았습니다. 소유자 없는 unlock, lease 유지, wait 전략을 각각 분리해서 확인해야 했습니다.
공통 helper 하나가 여러 임계 구역에 같은 위험을 전파하고 있었습니다
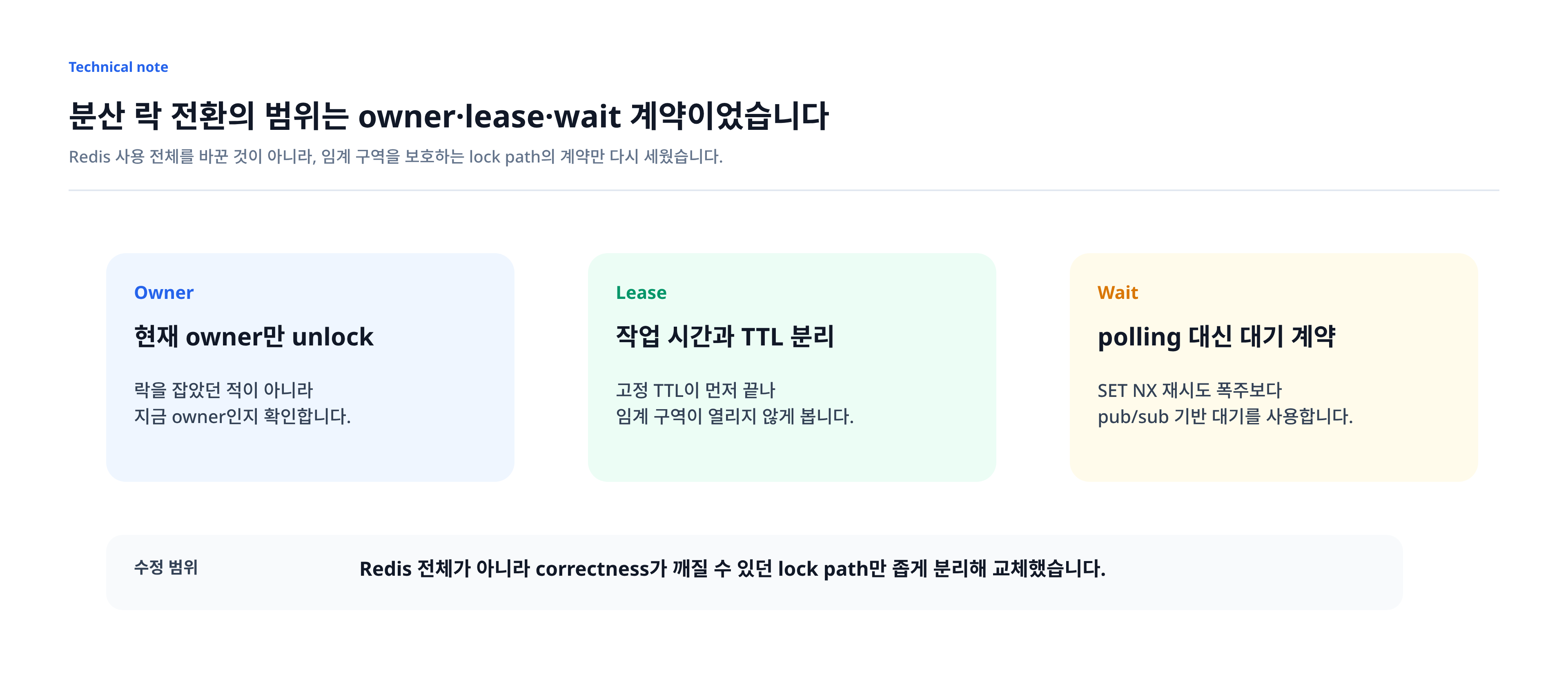
RedisSpinLock은 한 군데에서만 쓰이는 특수 구현이 아니었습니다. 크레딧 차감, 드라이브 정리 배치, 자동화 timeout, quota 등록처럼 동시에 하나만 실행돼야 하는 경로에 공통 helper로 묶여 있었습니다. 그래서 이 문제는 “락 하나가 조금 불편했다”는 수준이 아니었습니다. owner 검증, lease 관리, wait 전략이 helper 하나를 통해 여러 critical path에 전파되고 있었습니다.
당시 구현은 겉으로는 단순했습니다.
- 획득:
SET key value NX EX ttl - 해제:
DEL key - 대기:
sleep(100ms)기반 polling loop
문제는 단순함 자체가 아니라 계약의 조합이었습니다. 획득 시에는 key에 value를 넣지만, 해제 시에는 그 value를 다시 확인하지 않고 key 자체를 삭제했습니다. 대기 전략 역시 lock holder가 언제 끝나는지에 대한 신호가 아니라 주기적인 재시도에 의존했습니다. owner, lease, wait가 하나의 계약으로 맞물려 있지 않고 서로 다른 의미로 흩어져 있었던 셈입니다.
그래서 전환 범위도 Redis 전체가 아니라 이 세 계약으로 좁혔습니다. 현재 owner만 unlock할 수 있는지, 작업 시간이 길어져도 lease가 먼저 끝나지 않는지, 경합 중 대기가 Redis 재시도 폭주로 이어지지 않는지를 각각 분리해 봐야 했습니다. 이 기준이 있어야 Redisson 도입이 “라이브러리 교체”가 아니라, 깨질 수 있던 lock contract를 다시 세운 작업으로 읽힙니다.
이런 구현은 정상 경로에서는 잘 드러나지 않습니다. lock을 획득한 요청이 TTL 안에 일을 마치고 바로 해제하면 아무 일도 없는 것처럼 보입니다. 하지만 분산 락이 필요한 이유는 그런 정상 경로 때문이 아닙니다. 예측하지 못한 지연, 긴 작업, 경합, 일시적인 pause처럼 타이밍이 비틀리는 순간에도 의미가 유지돼야 하기 때문입니다.
blind unlock은 시간축이 어긋날 때 드러납니다
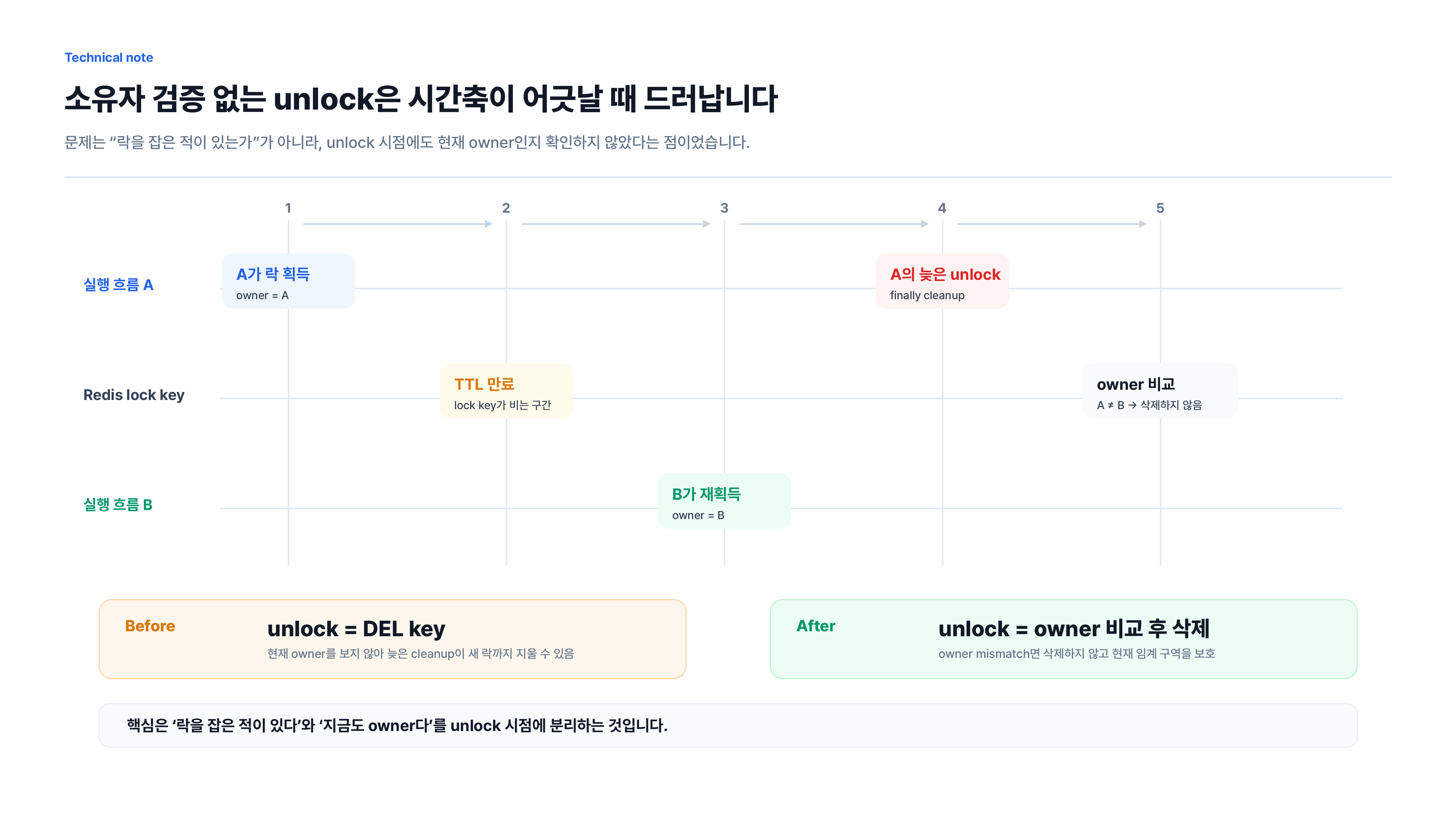
blind unlock의 위험은 단순히 DEL key가 위험하다는 말로는 충분히 설명되지 않습니다. 실제 문제는 시간축 위에서 owner의 의미가 바뀌는데, unlock 코드가 그 변화를 확인하지 않는 데 있습니다.
- A가 lock을 획득합니다.
- A의 작업이 길어집니다.
- lock TTL이 먼저 만료됩니다.
- B가 같은 key로 lock을 획득합니다.
- A가 뒤늦게 finally 블록에서 unlock을 호출합니다.
- Redis key만 보면 같은 key이므로 B의 lock이 삭제됩니다.
이 지점에서 unlock은 cleanup이 아니라 상태 변경 작업입니다. 락을 잡은 적이 있다는 사실과, 지금도 그 락의 owner라는 사실은 다릅니다. 분산 락 구현이 이 둘을 구분하지 못하면 finally 블록은 안전장치가 아니라 다른 요청의 임계 구역을 열어버리는 코드가 됩니다.
fixed TTL과 polling 역시 같은 맥락에서 문제였습니다. blind unlock은 owner 검증 부재의 직접 결과이고, TTL 만료는 lease 관리가 고정값에 묶여 있었기 때문에 발생합니다. polling wait는 holder의 종료 신호와 분리된 채 Redis에 재시도를 누적합니다. 이 셋은 서로 얽혀 있었지만 같은 문제는 아니었습니다.
lock path가 지켜야 할 계약을 다시 썼습니다
라이브러리를 고르기 전에 lock path가 만족해야 할 조건을 먼저 다시 정리했습니다.
이 기준이 먼저 서야 어떤 선택이 현실적인지 판단할 수 있었습니다. 목표는 “더 좋은 락 라이브러리 도입”이 아니라, 가장 위험한 실패 시나리오를 줄이면서 변경 범위를 lock path 안으로 최대한 가두는 것이었습니다.
대안은 세 가지였습니다
무엇을 넣을지보다 무엇을 버릴지를 먼저 정리해야 했습니다.
| 대안 | 좋은 점 | 한계 | 이번 선택 |
|---|---|---|---|
| custom 구현 보수 | owner token, compare-and-delete Lua, TTL 연장, wait 개선을 직접 붙일 수 있습니다. | 결국 분산 락 라이브러리를 다시 만들고 검증하는 일에 가까웠습니다. | 제외 |
Redisson RLock | owner-safe unlock, watchdog, pub/sub wait를 즉시 활용할 수 있습니다. | 별도 client와 운영 표면이 늘어납니다. | 채택 |
| fencing token 계열 | stale owner의 write까지 더 강하게 통제할 수 있습니다. | 호출 계약과 저장소 계약까지 함께 바뀌어야 하고 적용 범위가 커집니다. | 이번 범위 밖 |
여기서 중요한 건 Redisson을 선택한 이유도 이론적으로 가장 강한 답이어서가 아니었습니다. 현재 시스템에서 가장 위험한 실패 시나리오를 가장 좁은 범위 안에서 먼저 줄일 수 있는 선택이었기 때문입니다. 기존 custom path를 계속 보강하려면 결국 owner 확인, lease 연장, wait 전략을 직접 다시 구현해야 했습니다. Redisson의 lock path는 unlock 시 owner 확인과 lease 관리 계약을 라이브러리 수준으로 가져오게 해 주지만, fencing token처럼 저장소 write authority까지 보장하는 문제는 여전히 별도 설계 영역으로 남겼습니다.
Redis 전체가 아니라 lock path만 바꿨습니다
이번에 바꾼 범위는 Redis 전체가 아니었습니다. 기존 Spring Data Redis와 Lettuce 기반 cache, session, Pub/Sub, Streams는 유지하고, withLock() 경로 안쪽만 Redisson RLock으로 교체했습니다. 이 선을 명확히 그은 이유는 이번 작업의 목표가 Redis integration migration이 아니라 lock correctness 복구였기 때문입니다.
구현 관점에서 바뀐 계약은 세 가지였습니다.
unlock()은 현재 스레드가 실제 owner인지 확인한 뒤에만 수행합니다.- explicit
leaseTime없이 lock을 획득해 watchdog 경로를 사용합니다. - lock 전용 Redisson client를 별도 pool 설정과 함께 둡니다.
이 세 가지는 각각 owner 검증, lease 관리, wait 전략을 다시 맞추는 역할을 합니다. 중요한 건 기능이 늘었다는 사실보다, 이전 구현에서 서로 느슨하게 흩어져 있던 의미를 하나의 contract로 묶었다는 점입니다. 락을 잡은 주체, 락을 유지하는 방식, 기다리는 방식이 서로 다른 규칙으로 움직이면 정상 경로에서는 문제가 없어 보여도 지연이나 재획득이 섞이는 순간 경계가 무너집니다.
공용 lock wrapper도 일부러 좁게 설계했습니다. timeout은 0, 양수, 음수 세 경우로만 나눴습니다. 0이면 즉시 획득, 양수면 timed acquisition, 음수면 무기한 대기입니다. 중요한 건 양수 timeout 경로에서도 explicit leaseTime을 넘기지 않았다는 점입니다. call site가 기대하는 wait semantics는 유지하되 lease는 watchdog 계약에 맡기도록 정리했습니다.
운영 경계도 함께 나눴습니다. lock 전용 Redisson client는 기본 Redis client와 분리했고, connection과 subscription 자원도 보수적으로 떼어 놨습니다. Redis 전역을 다시 가져간 것이 아니라 correctness가 실제로 문제였던 path를 별도 운영면으로 분리한 셈입니다. 이 덕분에 변경 후 문제가 생겨도 cache나 session 경로가 아니라 lock client, lock wait, watchdog, subscription 사용량부터 좁혀볼 수 있었습니다.
검증은 “빠른가”보다 “위험한 순서를 막는가”를 봤습니다
이 변경에서 더 중요한 검증은 성능 수치가 아니라, 기존에 위험했던 시나리오를 더 이상 허용하지 않는지였습니다.
| 검증 기준 | 기존 구현 | 변경 후 기대 |
|---|---|---|
| TTL 만료 직후 재획득 후 이전 요청 unlock | 다음 요청의 락을 지울 수 있습니다. | 현재 owner가 아니면 unlock이 실패해야 합니다. |
| 작업 시간이 TTL보다 길어진 경우 | holder가 아직 작업 중인데 락이 먼저 풀릴 수 있습니다. | watchdog로 lease가 유지돼야 합니다. |
| 경합이 긴 경우 | SET NX 재시도가 누적됩니다. | pub/sub 기반 대기로 전환됩니다. |
| Redis timeout과 contention 구분 | 운영에서 같은 실패처럼 보일 수 있습니다. | 예외와 lock wait를 더 분리해서 볼 수 있어야 합니다. |
테스트는 단순히 동시에 여러 스레드를 실행하는 방식으로 끝내지 않았습니다. 실제 문제는 “동시성”보다 “시간축이 어긋난 상태에서 이전 owner가 뒤늦게 행동하는 상황”에서 발생했기 때문입니다. 그래서 현재 holder가 아닌 스레드의 unlock, TTL을 초과한 작업, 재획득 이후 이전 요청의 cleanup처럼 순서를 고정해서 재현해야 했습니다.
핵심 시나리오는 다음처럼 잡을 수 있습니다.
1. A가 lock을 획득한다.
2. A의 작업 시간이 lease 기준을 넘기도록 지연시킨다.
3. B가 같은 lock을 획득할 수 있는 조건을 만든다.
4. A가 뒤늦게 unlock을 호출한다.
5. B의 lock이 삭제되지 않는지 확인한다.이 테스트가 중요한 이유는, 분산 락의 실패가 대부분 정상적인 단위 테스트에서는 보이지 않기 때문입니다. 락을 잡고 바로 해제하는 테스트는 lock API 호출이 가능한지만 확인할 뿐, owner contract가 깨졌을 때 어떤 일이 생기는지는 확인하지 못합니다. 이번 문제의 본질은 API 사용법이 아니라 시간축 위에서 owner 의미가 유지되는지였습니다.
운영에서 같이 봐야 하는 지표도 달라졌습니다
분산 락 구현을 Redisson으로 바꾼다고 해서 운영에서 확인해야 할 항목이 사라지는 것은 아닙니다. 오히려 직접 구현이 감추고 있던 계약이 라이브러리 설정과 운영 지표로 이동합니다. 그래서 코드 변경 이후에는 lock wait, lease 연장, Redis 연결, subscription 사용량을 같은 묶음으로 봐야 합니다.
먼저 확인할 것은 lock 획득 실패와 작업 실패를 분리하는 일입니다. 락을 얻지 못한 것은 임계 구역에 들어가지 못했다는 의미이고, 임계 구역에 들어간 뒤 실패한 것은 도메인 작업이 실패했다는 의미입니다. 둘을 같은 예외로 묶으면 운영 로그에서는 모두 “작업 실패”처럼 보입니다. wrapper에서는 lock acquisition timeout, interrupted wait, business exception을 구분해서 남기는 편이 더 안전합니다.
두 번째는 watchdog이 정상적으로 동작할 수 있는 조건입니다. watchdog은 holder가 살아 있고 Redis와 계속 통신할 수 있을 때 lease를 연장합니다. 따라서 thread starvation, 긴 STW pause, Redis connection pool 고갈이 있으면 watchdog 자체도 제때 움직이지 못할 수 있습니다. 이 경우에는 Redisson을 쓴다는 사실만으로 충분하지 않고, lock path의 executor 상태와 Redis client 상태를 함께 봐야 합니다.
세 번째는 wait 전략입니다. polling 기반 SET NX 재시도는 경합이 커질수록 Redis에 같은 요청을 반복해서 보냅니다. Redisson의 pub/sub 기반 대기는 이 부담을 줄여 주지만, subscription 연결도 운영 자원입니다. lock 전용 client를 분리했다면 connection 수와 subscription 수가 기대 범위 안에 있는지도 같이 관찰해야 합니다.
이 변경이 닫은 것과 닫지 않은 것

변경 후에는 동일한 순서로 재현하던 blind unlock 경로가 다시 나타나지 않았고, 장시간 작업 중 TTL 만료로 임계 구역이 다시 열릴 가능성도 낮아졌습니다. polling 기반 대기를 pub/sub 기반 wait로 바꾸면서 경합 시 Redis에 쌓이는 재시도 부담도 함께 줄었습니다. 여기까지가 이번 작업에서 검증한 범위입니다.
하지만 이 지점에서 과장하면 오히려 더 위험합니다. watchdog은 살아 있는 holder의 lease를 연장해 주는 장치이지, owner가 시간축 위에서 stale해지는 모든 반례를 없애는 장치는 아닙니다. 긴 GC pause, STW, 네트워크 분리 같은 상황에서는 owner가 여전히 살아 있는 것처럼 보여도 lock service 기준으로는 이미 죽은 쪽이 될 수 있습니다.
그 반례를 시간축으로 끝까지 따라가 보면 이런 시나리오가 남습니다.
- Thread A가 락을 획득하고 외부 시스템 상태나 DB row를 읽어 로컬 문맥을 만듭니다.
- 그 직후 GC pause, STW, 혹은 Redis와의 네트워크 분리가 발생합니다.
- watchdog 연장이 멈추고 lease가 만료됩니다.
- Thread B가 같은 락을 획득하고 더 새로운 상태로 작업을 끝냅니다.
- A가 뒤늦게 깨어나면, 자기 lease가 이미 끝났다는 사실을 모른 채 오래된 문맥으로 후속 write를 시도할 수 있습니다.
이 단계에서 blind unlock은 이미 막혀 있습니다. A가 unlock()을 호출해도 더 이상 현재 owner가 아니므로 락은 풀리지 않습니다. 그런데 위험은 unlock이 아니라 write 쪽으로 이동합니다. 즉, 락을 잘못 해제하지 않게 된 것과 오래된 owner가 쓰기를 하지 못하게 된 것은 같은 문장이 아닙니다.
그래서 lock correctness와 write authority는 다른 층위로 봐야 합니다.
- lock correctness는 누가 owner인가, 누가 unlock할 수 있는가의 문제입니다.
- write authority는 시간이 지난 뒤에도 그 actor가 여전히 쓰기를 할 자격이 있는가의 문제입니다.
이 단계의 해법은 락 라이브러리 바깥으로 나갑니다. fencing token은 더 새로운 owner만 write할 수 있게 저장소에 epoch를 같이 전달합니다. conditional update는 읽은 버전이 아직 유효할 때만 쓰기를 허용하는 compare-and-set 계약입니다. version check는 write path가 lock 외부 시간축을 직접 검사하게 만드는 장치입니다.
이번 작업은 여기까지 확장하지 않았습니다. 의도적으로 그렇게 끊었습니다. 소유자 검증 없이 unlock되는 경로와 고정 TTL 문제를 먼저 제거하는 것이 더 시급했고, 오래된 owner가 뒤늦게 write하는 문제는 lock migration이 아니라 저장소의 쓰기 권한 계약을 다시 설계해야 하는 영역에 가깝기 때문입니다.
운영에서 달라진 확인 순서
이 변경 이후 분산 락 문제를 볼 때의 확인 순서가 달라졌습니다. 예전에는 “락이 잡혔는가”와 “작업이 끝났는가”를 중심으로 봤다면, 이제는 먼저 현재 owner가 누구인지, lease가 어떤 계약으로 유지되는지, 대기 중인 요청이 polling인지 pub/sub wait인지를 나눠 봅니다.
장애 대응에서도 기준이 더 좁아졌습니다. 같은 key에서 문제가 보이면 Redis 전체 사용 경로를 의심하기보다 lock 전용 client, lock wait 시간, watchdog 연장 여부, owner mismatch 로그를 먼저 확인합니다. 반복 실패가 있다면 그다음에야 DB write authority나 fencing token 같은 다음 층위의 문제로 넘어갑니다.
이번 변경은 분산 락의 모든 반례를 닫은 작업이 아닙니다. 닫은 것은 소유자가 아닌 흐름이 다른 요청의 락을 지우는 경로였습니다. 남은 문제도 분명합니다. 오래된 owner가 뒤늦게 write를 시도하는 반례는 lock library만으로 끝나지 않고, 저장소의 version check나 fencing token 같은 별도 계약이 필요합니다.
Redisson으로 바꾼 뒤에도 안전성은 라이브러리 이름에서 나오지 않습니다. custom lock helper 안에 숨어 있던 owner, lease, wait 계약을 더 명시적인 lock path로 옮긴 것이 핵심이었습니다. 분산 락에서 실제로 위험한 순간은 평상시 API 호출이 아니라 시간축이 어긋나는 순간입니다. unlock이 지연되고, lease가 끝나고, 다음 요청이 같은 key를 잡았을 때도 owner 의미가 유지되는지 확인할 수 있어야 합니다.