외부 도구 호출 결과에 DLP 스캔을 붙이면서 처음 부딪힌 질문은 API를 어디서 호출할지가 아니었습니다. 먼저 정해야 했던 것은 이 경로의 DLP가 사용자 응답을 실시간으로 차단하기 위한 통제인지, 감사와 탐지를 위한 기록 경로인지였습니다.
동기 차단이 필요한 경로라면 결과를 반환하기 전에 판정이 끝나야 합니다. 하지만 외부 도구 응답마다 같은 방식으로 DLP API를 기다리면, DLP의 지연과 장애가 사용자 요청 전체의 지연과 실패로 번집니다. 한 요청 안에서 도구 호출이 여러 번 이어지는 구조에서는 스캔 하나의 tail latency가 응답 흐름 전체를 끌고 갈 수도 있습니다.
그래서 이번 작업은 단순한 비동기화가 아니라 응답 경로와 감사 경로의 실패 경계를 분리하는 문제로 잡았습니다. 사용자에게 돌려줄 응답은 짧게 유지하되, 스캔 대상·처리 상태·실패 원인은 나중에 다시 조회하고 재처리할 수 있는 단위로 남기는 것이 목표였습니다.
정책 목적을 먼저 고정했습니다
DLP를 붙인다는 말만으로는 구현 방향이 정해지지 않습니다. 같은 “스캔”이라도 응답 전 차단, 사후 감사, 이상 징후 탐지는 서로 다른 실패 처리를 요구합니다. 응답 전 차단이 목적이면 스캔 실패를 요청 실패로 보는 것이 자연스럽지만, 감사 중심 경로라면 실패를 사용자 오류로 전파하는 것보다 실패 증거를 잃지 않는 것이 더 중요합니다.
이번 경로는 후자에 가까웠습니다. 외부 도구 호출 응답을 사용자에게 돌려주되, 어떤 응답이 스캔 대상으로 잡혔는지, 어떤 이벤트가 실패했는지, 어떤 실패를 다시 처리할 수 있는지를 운영자가 추적할 수 있어야 했습니다.
이 기준을 먼저 고정하니 설계에서 확인해야 할 질문도 달라졌습니다. DLP API 호출 자체가 성공했는가보다, 이벤트가 발행됐는가, 실패 상태가 남았는가, 재처리 가능 여부가 구분됐는가를 함께 봐야 했습니다.
정책 목적을 고정할 때는 다음처럼 경로를 나눠 봤습니다. 같은 DLP라는 이름을 쓰더라도 응답 전에 반드시 막아야 하는 경로와, 사후 감사 대상으로 남겨야 하는 경로는 실패 처리 방식이 달라야 합니다.
| 경로 | 정책 목적 | DLP 실패 시 기준 |
|---|---|---|
| 응답 전 차단 | 민감 정보가 사용자에게 전달되기 전에 판정 | 판정 실패를 요청 실패나 격리 대상으로 처리해야 합니다. |
| 사후 감사 | 어떤 응답이 스캔 대상이었는지 추적 | 사용자 응답보다 실패 이벤트와 재처리 근거를 남기는 것이 중요합니다. |
| 이상 징후 탐지 | 패턴과 반복 실패를 운영자가 확인 | 개별 요청 성공보다 상태 집계와 오류 유형 분리가 중요합니다. |
이번 경로는 두 번째에 가까웠습니다. 그래서 “보안보다 가용성을 우선한다”가 아니라, 사용자 응답과 감사 처리를 같은 실패 영역에 묶지 않는 것을 설계 기준으로 삼았습니다.
요구사항을 응답 경로와 감사 경로로 나눴습니다
처음에는 “DLP를 붙인다”는 요구사항이 하나처럼 보입니다. 하지만 실제로는 서로 다른 두 요구사항이 섞여 있었습니다.
- 사용자 응답 경로는 도구 호출 결과를 안정적으로 반환해야 합니다.
- 감사 경로는 스캔 대상, 처리 결과, 실패 이벤트를 추적 가능하게 남겨야 합니다.
이 둘을 같은 트랜잭션처럼 묶으면 구현은 단순해 보입니다. 하지만 외부 DLP API가 느려지거나 실패하는 순간 사용자 응답도 같은 운명을 갖게 됩니다. 반대로 둘을 완전히 분리해버리면 사용자는 빠르게 응답을 받지만, 스캔 실패가 조용히 사라질 수 있습니다.
그래서 목표는 단순히 “비동기로 만들기”가 아니었습니다. 응답 경로는 짧게 유지하고, 감사 경로는 실패를 잃지 않도록 만드는 것이었습니다. 이 기준이 없으면 성능 개선처럼 보이는 구조가 실제로는 보안 이벤트를 삼키는 구조가 될 수 있습니다.
동기 스캔은 단순하지만 장애 전파 범위가 큽니다
동기 스캔 구조에서는 사용자 응답이 외부 DLP API의 상태에 직접 묶입니다. DLP API 호출 시간이 p99 구간에서 튀면 사용자 응답도 같이 밀립니다. 네트워크 오류가 발생하면 재시도 시간이 요청 처리 시간에 누적됩니다. 도구 호출이 여러 번 이어지는 요청에서는 이 지연이 한 번이 아니라 여러 번 더해질 수 있습니다.
기존 채팅 DLP 큐와 같은 경로를 공유하는 방식도 검토할 수 있습니다. 구현과 운영 지점은 줄어듭니다. 하지만 채팅 메시지와 외부 도구 호출 응답은 발생 패턴이 다릅니다. 도구 호출 이벤트가 짧은 시간에 몰리는 구간에서 같은 큐를 공유하면, 도구 호출 쪽 burst가 기존 채팅 DLP 처리 지연으로 전파될 수 있습니다.
| 선택지 | 좋은 점 | 주의할 점 |
|---|---|---|
| 동기 스캔 | 응답 전에 스캔 결과를 확정할 수 있습니다. | 외부 DLP 지연과 장애가 사용자 응답 시간에 직접 반영됩니다. |
| 기존 큐 공유 | 운영 지점과 구현 경로가 단순합니다. | 도구 호출 이벤트가 기존 채팅 DLP 지연으로 번질 수 있습니다. |
| 별도 비동기 경로 | 응답 경로와 감사 경로를 분리할 수 있습니다. | 실패 이벤트를 상태로 남기고 재처리 기준을 별도로 관리해야 합니다. |
이 비교에서 남는 기준은 처리량보다 장애 전파 범위였습니다. 사용자 응답, 기존 채팅 DLP, 외부 도구 호출 DLP가 같은 실패 영역에 묶이면 작은 지연도 여러 경로의 운영 문제로 번질 수 있습니다. 그래서 큐를 나눌지, 응답 전에 기다릴지, 실패를 어디에 남길지는 모두 같은 질문으로 돌아왔습니다. DLP 인프라의 지연과 장애가 어디까지 전파되어야 하는가.
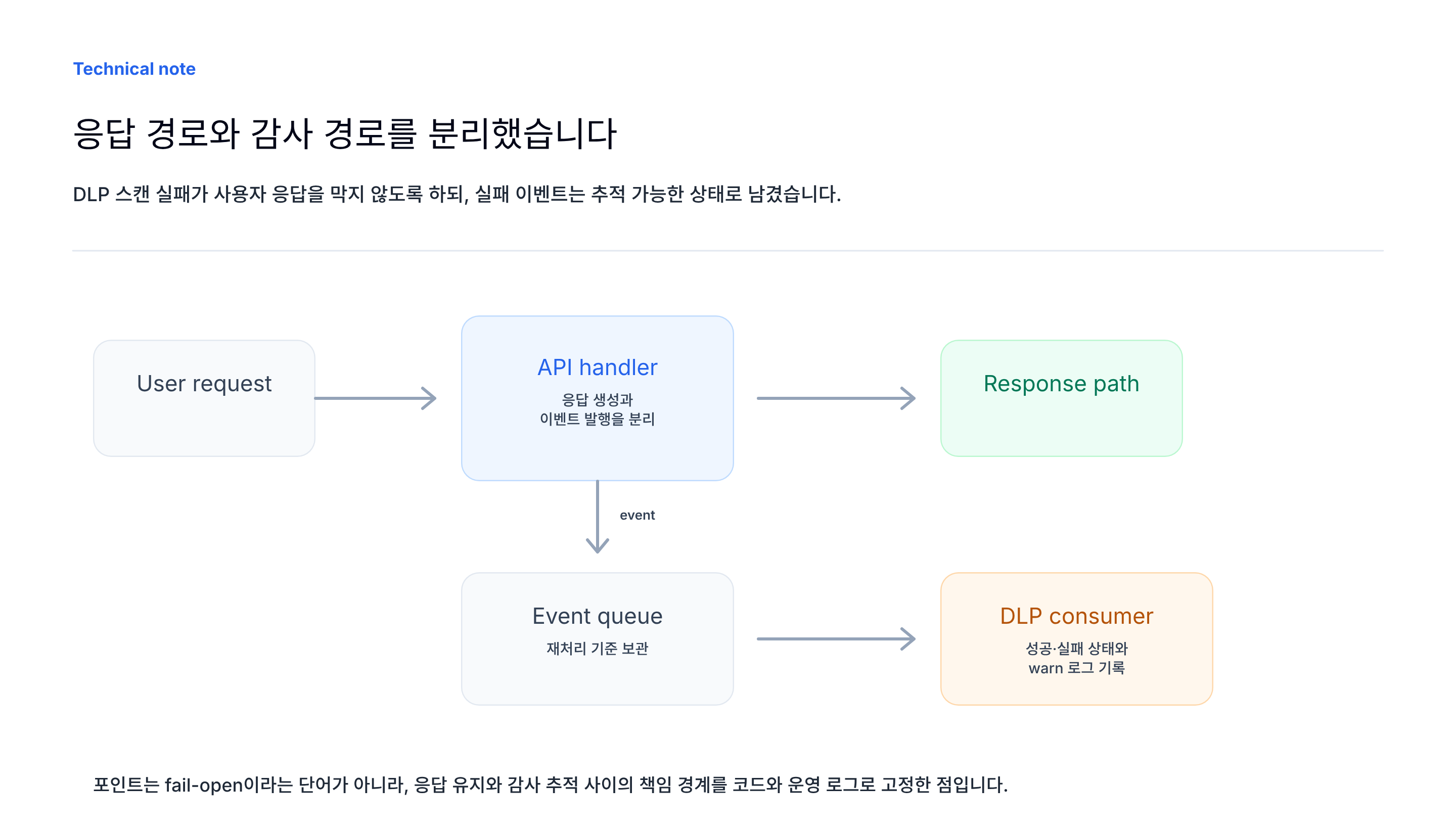
응답 경로는 이벤트 발행까지만 책임지게 했습니다
최종 구조에서는 DLP Interceptor가 외부 도구 호출 응답을 캡처하고, 스캔에 필요한 최소 정보와 식별자를 이벤트로 분리합니다. 사용자 응답 경로에서는 이벤트 발행까지만 수행하고, 실제 DLP API 호출은 Consumer가 비동기로 처리합니다.
이렇게 나누면 사용자 응답은 외부 DLP API 호출 시간을 직접 기다리지 않습니다. 대신 감사 경로는 별도의 책임을 갖습니다. 이벤트를 잃지 않아야 하고, 실패를 상태로 남겨야 하며, 재처리가 가능한 실패와 그렇지 않은 실패를 구분해야 합니다.
동기 처리였다면
- 사용자 응답이 외부 DLP API 지연에 묶임
- DLP 장애가 응답 장애로 전파됨
- 재시도 시간이 요청 처리 경로에 누적됨
비동기 분리 후
- 응답 경로는 이벤트 발행까지만 수행
- 스캔 실패는 상태와 로그로 보존
- 큐와 Consumer 기준으로 재처리 가능
이벤트를 설계할 때 가장 먼저 본 것은 메시지에 무엇을 담을지였습니다. 스캔 대상 원문을 무분별하게 로그나 메시지에 남기면 DLP를 붙이면서 오히려 민감 정보 노출면을 넓힐 수 있습니다. 그래서 발행 전에는 민감 키를 마스킹하고, 요청 식별자, 처리 상태, 재시도 횟수, 마지막 오류 같은 운영 정보만 추적 가능하게 남겼습니다.
이벤트는 “나중에 다시 판단할 수 있는 단위”여야 했습니다
비동기 구조에서 이벤트는 단순한 메시지가 아닙니다. 장애가 끝난 뒤 운영자가 다시 판단할 수 있는 최소 단위입니다. 그래서 이벤트를 설계할 때도 payload를 그대로 큐에 넣는 방식은 피해야 했습니다.
이벤트에는 세 가지 성격의 정보가 필요했습니다.
| 정보 | 목적 | 주의점 |
|---|---|---|
| 요청 식별자 | 장애 이후 어떤 요청이 영향을 받았는지 추적 | 사용자 입력 원문을 식별자로 쓰지 않음 |
| 스캔 대상 메타데이터 | 어떤 종류의 도구 응답이었는지 분류 | 민감 값은 마스킹하거나 저장하지 않음 |
| 처리 상태 | 성공, 실패, 재처리 가능 여부를 구분 | 로그에만 의존하지 않고 상태로 남김 |
이렇게 이벤트를 잡아두면 장애가 났을 때 “DLP가 실패했다”에서 멈추지 않습니다. 어떤 요청 범위가 영향을 받았는지, 어떤 실패가 재처리 가능한지, 어떤 오류는 정책상 재처리하면 안 되는지 나눌 수 있습니다.
실패는 로그 한 줄이 아니라 상태여야 합니다
비동기 구조에서 가장 위험한 구현은 실패를 조용히 삼키는 것입니다. 사용자 응답을 유지한다는 이유로 스캔 실패를 warn 로그 한 줄로만 남기면, 장애가 끝난 뒤 어떤 응답이 스캔되지 않았는지 다시 찾기 어렵습니다.
그래서 실패 이벤트는 별도의 상태로 남겨야 했습니다. 실패 상태가 있어야 운영자가 할 수 있는 일이 생깁니다. 어떤 이벤트가 재처리 대상인지, 어떤 이벤트가 정책상 처리 불가능한 실패인지, 어떤 오류가 반복되는지, 장애 시간대에 영향을 받은 범위가 어디까지인지 다시 조회할 수 있습니다.
이 차이는 작지 않습니다. 로그는 검색할 수 있지만, 상태는 처리할 수 있습니다. 실패 이벤트가 상태로 남아 있으면 다시 큐에 넣을지, 일정 횟수 이상 실패한 이벤트를 별도 확인 대상으로 보낼지, 특정 오류 코드는 재시도하지 않을지 결정할 수 있습니다.
재시도는 보호 장치이면서 장애 증폭 요인이 될 수 있습니다
재시도는 안전장치처럼 보이지만, 외부 API 장애가 길어질 때는 오히려 장애를 키울 수 있습니다. 같은 이벤트가 반복해서 외부 API를 호출하면 큐 지연이 늘고, 호출 한도도 더 빨리 소진됩니다. 특히 DLP처럼 외부 서비스와 연결된 경로에서는 재시도 횟수를 크게 잡는다고 안정성이 좋아지는 것이 아닙니다.
부하 테스트에서 확인한 GCP DLP 응답 시간 p99는 336ms 수준이었습니다. 이 값을 절대적인 SLA로 본 것은 아니지만, 애플리케이션 쪽 timeout과 재시도 정책을 정할 때 참고할 수 있는 기준으로 사용했습니다. 애플리케이션 재시도는 1회로 제한하고, 반복 실패는 이벤트 상태와 Consumer 재처리 정책으로 넘겼습니다.
이렇게 한 이유는 단순합니다. 사용자 요청 경로에서 재시도 시간을 계속 쌓지 않고, 비동기 처리 경로에서 실패를 관측 가능한 형태로 다루기 위해서입니다. 재시도는 실패를 감추기 위한 장치가 아니라, 실패를 분류하고 다음 처리를 결정하기 위한 장치여야 했습니다.
큐 분리는 처리량보다 장애 격리를 위한 선택이었습니다
DLP 작업을 기존 채팅 DLP 큐와 함께 처리할 수도 있었습니다. 하지만 도구 호출 응답은 채팅 메시지와 발생 패턴이 다릅니다. 하나의 사용자 요청 안에서 여러 도구 호출이 연속으로 발생할 수 있고, payload 크기도 일정하지 않습니다.
그래서 큐를 나눈 이유는 단순한 처리량 확보가 아니었습니다. 도구 호출 DLP가 밀리더라도 채팅 DLP까지 같이 밀리지 않게 하고, 반대로 채팅 DLP 처리량이 높아지는 시간대에도 도구 호출 스캔 실패를 별도로 관측할 수 있게 하는 것이 목적이었습니다.
모니터링도 큐 길이 하나로 끝나지 않습니다. 큐 길이는 현재 밀림을 보여주지만, 왜 밀렸는지는 말해주지 않습니다. Consumer 처리 시간, 외부 DLP API 응답 시간, 재시도 횟수, 실패 상태 비율을 함께 봐야 합니다. 특히 p99 지연이 튀는 외부 API라면 평균 응답 시간만으로는 충분하지 않습니다.
이 설계가 닫은 것과 닫지 않은 것
이 설계는 모든 DLP 경로에 맞는 해법이 아닙니다. 응답 자체를 반드시 차단해야 하는 정책이라면 사용자 응답 경로와 스캔 경로를 분리하는 방식은 맞지 않습니다. 특정 데이터가 외부로 나가기 전에 반드시 판정되어야 하는 경로라면, 동기 차단이나 격리된 판정 경로를 먼저 검토해야 합니다.
이번 구조가 맞았던 이유는 정책 목적이 달랐기 때문입니다. 이 경로의 DLP는 사용자 응답을 실시간으로 막는 장치라기보다, 외부 도구 호출 응답을 감사와 탐지 대상으로 남기는 역할이 컸습니다. 그래서 사용자 응답을 외부 DLP API의 가용성에 묶기보다, 실패 증거를 잃지 않고 나중에 다시 처리할 수 있게 만드는 쪽을 선택했습니다.
닫은 문제와 닫지 않은 문제도 분리해서 봐야 합니다.
- 닫은 것: 외부 DLP API의 지연이 사용자 응답 지연으로 직접 번지는 경로를 줄였습니다.
- 닫은 것: 스캔 실패가 로그 한 줄로만 흩어지지 않고 상태와 재처리 대상으로 남도록 했습니다.
- 닫은 것: 도구 호출 DLP의 burst가 기존 채팅 DLP 경로와 같은 큐에서 섞이지 않도록 했습니다.
- 닫지 않은 것: 즉시 차단이 필요한 정책 경로까지 이 구조로 처리할 수 있는 것은 아닙니다.
- 닫지 않은 것: 외부 DLP 판정 자체의 정확도나 정책 룰 품질은 별도의 문제입니다.
비동기로 분리했다는 사실만으로 안전해지지는 않습니다. 이 경로에서 먼저 정해야 했던 것은 사용자에게 즉시 보여야 하는 실패와, 운영자가 나중에 추적해도 되는 실패의 경계였습니다. DLP처럼 보안 정책과 사용자 응답이 만나는 기능에서는 이 경계가 흐려지는 순간 응답 지연, 감사 누락, 과도한 차단이 한 번에 섞입니다.
운영에서 달라진 확인 순서
분리 이후 사용자 응답 경로는 외부 DLP API 대기와 직접 결합되지 않도록 정리했습니다. DLP 인프라 장애 시나리오에서는 사용자 요청을 그대로 실패시키는 대신, 스캔 실패 이벤트를 상태와 warn 로그로 남기고 재처리 대상으로 보냈습니다. 즉 “실패를 숨긴다”가 아니라, 사용자 응답 경로와 감사 경로가 각각 어떤 실패를 책임질지 나눈 것입니다.
운영에서 보는 순서도 달라졌습니다. 예전에는 사용자 응답 지연을 보면 외부 도구 호출, DLP API, 기존 채팅 DLP 큐를 함께 의심해야 했습니다. 이제는 먼저 이벤트 발행 여부와 큐 대기 시간, Consumer 처리 시간, 외부 DLP API p95/p99, 실패 상태 비율을 나눠 봅니다. 사용자 응답 경로의 문제인지, 감사 경로의 처리 지연인지, 외부 DLP API의 tail latency인지 출발점을 분리할 수 있습니다.
DLP 경로를 다시 점검할 때는 사용자 응답 로그보다 큐와 실패 상태를 먼저 봅니다. 응답 경로를 짧게 유지하려면, 그 대신 감사 경로에는 이벤트 발행 여부, 큐 대기 시간, Consumer 처리 결과, 외부 DLP 실패 상태가 남아 있어야 합니다. 이 순서가 있어야 지연이 사용자 응답 경로에서 생긴 문제인지, 감사 경로에서만 밀린 문제인지, 외부 DLP API의 tail latency인지 분리해서 볼 수 있습니다.