런치챗 초기 배포는 GitHub Actions에서 이미지를 만들고 두 대의 애플리케이션 서버에 동시에 반영하는 방식이었습니다. 배포 시간만 보면 효율적이었지만, 실제 트래픽을 받기 시작하면서 기준이 달라졌습니다.
배포에서 먼저 확인해야 할 것은 “얼마나 빨리 바뀌는가”보다 배포 중에도 요청을 받을 수 있는 서버가 남아 있는가였습니다. 병렬 배포는 짧은 시간 안에 끝나는 대신, 두 서버가 함께 재시작되는 순간과 실패 후 판단해야 할 상태를 동시에 만들고 있었습니다.
배포에서 가장 위험했던 순간은 새 이미지를 올리는 명령 자체가 아니었습니다. 두 대뿐인 서버 중 하나가 준비되지 않은 상태에서 다음 서버까지 교체하면, 롤링 배포라는 이름을 붙여도 실제로는 병렬 장애와 비슷한 상황이 됩니다. 여기서는 CI/CD 도구 교체보다, 작은 서비스에서도 배포를 트래픽 전환 절차로 다뤄야 했던 이유를 중심으로 정리합니다.
먼저 배포의 기준을 다시 세웠습니다
배포 전략을 다시 보면서 기준을 네 가지로 좁혔습니다.
초기 방식은 빠르기는 했지만, 이 기준을 안정적으로 만족시키기 어려웠습니다. 특히 “배포 명령이 성공했는가”와 “사용자 요청을 계속 처리할 수 있는가”는 다른 문제였습니다.
병렬 배포는 실패 범위를 한 번에 키웠습니다
초기에는 GitHub Actions 하나로 CI와 CD를 함께 처리했습니다. 빌드, 이미지 생성, 모니터링 배포, 애플리케이션 서버 배포가 하나의 워크플로 안에 있었고, 두 애플리케이션 서버는 병렬로 배포했습니다.
name: LunchChat CI/CD Pipeline
on:
push:
branches: [main, 'dev/**']
jobs:
build-and-push:
runs-on: ubuntu-latest
steps:
- name: Build application
run: ./gradlew build -x test --no-daemon --parallel
- name: Build and push Docker image
uses: docker/build-push-action@v5
deploy-server1:
needs: [build-and-push, deploy-monitoring]
runs-on: ubuntu-latest
deploy-server2:
needs: [build-and-push, deploy-monitoring]
runs-on: ubuntu-latest구성만 보면 단순합니다. 하지만 두 서버가 같은 시점에 새 이미지로 바뀌면, 로드밸런서 뒤에 서버가 두 대 있더라도 배포 중 요청을 받을 수 있는 인스턴스가 일시적으로 줄어듭니다. 컨테이너가 재시작되는 시간, 애플리케이션 초기화 시간, DB 연결 준비 시간이 겹치면 짧은 요청 실패가 발생할 수 있습니다.
운영 관점에서 더 불편했던 부분은 실패 후 판단이었습니다.
- 두 서버가 동시에 바뀌면 문제가 새 버전 때문인지, 특정 서버 상태 때문인지 분리하기 어렵습니다.
- 한 서버는 성공하고 한 서버는 실패하면 현재 트래픽이 어느 버전으로 흐르는지 확인해야 합니다.
- 마이그레이션이 배포 흐름 안에 섞이면 어느 서버에서 실행됐는지 추적해야 합니다.
즉, 병렬 배포의 문제는 단순히 “잠깐 끊길 수 있다”가 아니었습니다. 실패가 발생했을 때 관측해야 할 상태가 한 번에 늘어난다는 점이 더 컸습니다.
롤링 배포로 변경 범위를 절반에서 끊었습니다
방향은 단순했습니다. 두 서버를 함께 바꾸지 않고, 한 서버를 배포한 뒤 검증이 끝나야 다음 서버로 넘어가도록 만들었습니다. 첫 번째 서버에서 문제가 확인되면 두 번째 서버는 그대로 둡니다. 이렇게 하면 이전 버전으로 살아 있는 서버가 남고, 실패 범위도 한 서버로 제한됩니다.
deploy-server1:
needs: [build-and-push, deploy-monitoring]
runs-on: ubuntu-latest
steps:
- name: Deploy to Server-1
run: |
export SERVER_NAME="Server-1"
export INCLUDE_DB_MIGRATION="true"
verify-server1:
needs: deploy-server1
runs-on: ubuntu-latest
deploy-server2:
needs: [build-and-push, verify-server1]
runs-on: ubuntu-latest
steps:
- name: Deploy to Server-2
run: |
export SERVER_NAME="Server-2"
export INCLUDE_DB_MIGRATION="false"이 구조에서는 배포 순서보다 다음 단계로 넘어가지 않을 조건을 만든 점이 더 컸습니다.
| 구분 | 병렬 배포 | 롤링 배포 |
|---|---|---|
| 서버 전환 | 두 서버가 동시에 새 버전으로 전환됩니다. | 한 서버씩 전환하고 검증 후 다음 서버로 넘어갑니다. |
| 실패 범위 | 두 서버 모두 영향을 받을 수 있습니다. | 첫 번째 서버에서 멈추면 이전 버전 서버가 남습니다. |
| 원인 추적 | 서버별 상태와 버전을 함께 확인해야 합니다. | 새 버전이 적용된 서버를 기준으로 좁힐 수 있습니다. |
| 마이그레이션 | 배포 흐름 안에서 실행 주체가 흐려질 수 있습니다. | 한 경로에서만 실행하도록 고정할 수 있습니다. |
롤링 배포는 배포 시간을 줄이는 선택은 아니었습니다. 대신 장애가 생겼을 때 “어디까지 바뀌었는지”를 설명하기 쉬운 구조였습니다.
GitHub Actions에는 빌드 책임만 남겼습니다
롤링 배포로 바꾼 뒤에도 불편은 남았습니다. 배포 로직이 GitHub Actions 파일 안에서 계속 커지고 있었기 때문입니다. 처음에는 워크플로 하나에 모아두는 편이 쉬웠지만, 시간이 지나면서 빌드 단계와 배포 단계의 관심사가 섞이기 시작했습니다.
대표적인 문제는 세 가지였습니다.
- 배포 순서와 서버별 조건이 CI 파일 안에서 길어졌습니다.
- 환경별 설정과 시크릿이 GitHub Actions 쪽에 과하게 모였습니다.
- 배포 절차를 바꾸기 위해 빌드 워크플로까지 함께 수정해야 했습니다.
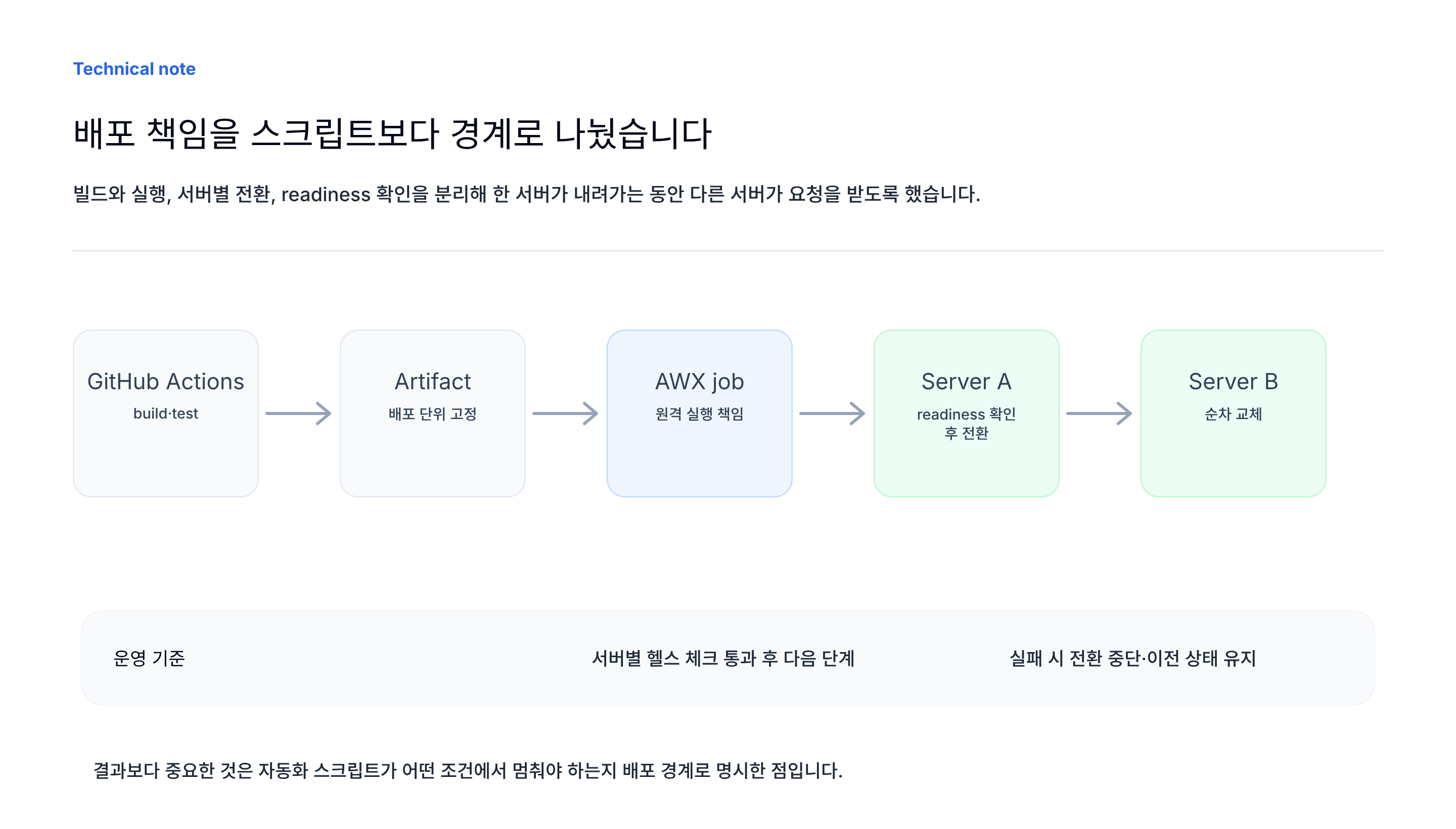
그래서 GitHub Actions는 빌드와 이미지 생성만 담당하도록 줄이고, 실제 배포 실행은 AWX와 Ansible Playbook으로 옮겼습니다.
name: LunchChat CI/CD Pipeline with AWX
jobs:
build-and-push:
runs-on: ubuntu-latest
outputs:
image-tag: ${{ steps.set-tag.outputs.IMAGE_TAG }}
steps:
- name: Build application with Gradle
run: ./gradlew build -x test
- name: Build and push Docker image
uses: docker/build-push-action@v5
deploy-app-servers:
needs: build-and-push
runs-on: ubuntu-latest
steps:
- name: Launch AWX job
run: |
awx job_templates launch "Deploy LunchChat App" \
--extra-vars "$EXTRA_VARS" \
--monitor배포 절차는 Ansible 쪽에서 순서를 보장하도록 했습니다.
- name: Deploy LunchChat Application
hosts: app_server
become: yes
gather_facts: no
serial: 1
tasks:
- name: Render docker-compose.yml
template:
src: templates/docker-compose.app.yml.j2
dest: "{{ app_dir }}/docker-compose.yml"
- name: Pull the new image and restart one instance
community.docker.docker_compose_v2:
project_src: "{{ app_dir }}"
pull: always
state: present
recreate: always
- name: Wait until the instance is ready for traffic
uri:
url: http://localhost:8080/actuator/health/readiness
status_code: 200
return_content: true
register: readiness
retries: 30
delay: 2
until: readiness.json.status == "UP"여기서 핵심은 serial: 1이었습니다. 롤링 배포 규칙을 스크립트 관습이 아니라 배포 도구의 실행 단위로 옮겼습니다. 실수로 두 서버가 동시에 배포되는 경로를 줄이는 것이 목적이었습니다.
readiness는 단순 ping보다 좁고 엄격해야 했습니다
롤링 배포에서 가장 중요한 판단 지점은 “다음 서버로 넘어가도 되는가”입니다. 이때 헬스체크가 프로세스 생존 여부만 보면 부족합니다. 컨테이너가 떠 있고 포트가 열려 있어도, 애플리케이션이 실제 요청을 받을 준비가 끝났다고 볼 수는 없습니다.
구분해서 보면 더 명확합니다.
| 확인 항목 | 의미 | 배포 판단에서의 역할 |
|---|---|---|
| Liveness | 프로세스가 살아 있는지 확인합니다. | 컨테이너 재시작 여부를 판단하는 데 가깝습니다. |
| Readiness | 실제 요청을 받을 준비가 됐는지 확인합니다. | 다음 서버로 넘어가도 되는지 판단하는 기준입니다. |
| 외부 의존성 | DB, Redis, 외부 설정, 내부 캐시 초기화 상태를 봅니다. | 초기화 중인 서버로 트래픽이 들어가는 문제를 줄입니다. |
작은 서비스에서도 이 구분은 중요했습니다. 서버가 두 대뿐이면 한 대의 readiness 실패가 전체 처리 용량의 절반에 해당합니다. 첫 번째 서버가 준비되지 않았는데 두 번째 서버 배포로 넘어가면, 롤링 배포를 했더라도 병렬 배포와 비슷한 문제가 다시 생깁니다. 따라서 health check는 프로세스 생존 확인에 머물면 부족하고, 적어도 애플리케이션이 요청을 받을 수 있는 상태인지까지 확인해야 했습니다.
롤링 배포는 순서보다 트래픽 전환 기준이 중요했습니다
서버를 한 대씩 바꾸는 것만으로는 충분하지 않았습니다. 배포 대상 서버가 언제 새 요청을 받지 않아야 하는지, 언제 다시 트래픽 대상으로 볼 수 있는지를 함께 정해야 했습니다. 그렇지 않으면 serial: 1로 실행해도 초기화 중인 서버로 요청이 들어가는 문제가 남습니다.
| 단계 | 확인 기준 |
|---|---|
| 배포 전 | 현재 요청을 처리할 서버가 최소 한 대 남아 있는지 확인 |
| 재시작 중 | 대상 서버가 새 요청을 받는 상태로 남지 않도록 트래픽 경로 확인 |
| 재시작 후 | 프로세스 생존이 아니라 readiness 기준으로 복귀 판단 |
| 다음 서버 전환 전 | 새 버전 서버의 주요 오류와 응답 상태를 먼저 확인 |
이 기준을 두면 배포가 단순히 “컨테이너를 새로 띄우는 작업”이 아니라, 요청을 받을 수 있는 서버 집합을 유지하면서 한 대씩 교체하는 절차가 됩니다.
롤백보다 먼저 필요한 것은 멈출 수 있는 기준이었습니다
배포 자동화에서 롤백을 먼저 떠올리기 쉽지만, 실제 운영에서는 롤백보다 먼저 필요한 것이 있습니다. 어느 시점에서 다음 단계를 멈출지입니다.
첫 번째 서버 배포 후 readiness가 실패하거나 5xx가 늘어나거나 반복 오류가 로그에 남는다면, 두 번째 서버는 건드리지 않는 편이 안전합니다. 이때 이전 버전으로 살아 있는 서버가 남아 있으면, 전체 롤백을 시작하기 전에도 서비스는 일부 용량을 유지할 수 있습니다.
배포 흐름은 다음처럼 단순하게 고정했습니다.
1. 새 이미지 빌드
2. Server-1 배포
3. Server-1 readiness 확인
4. 실패하면 Server-2 배포 중단
5. 성공하면 Server-2 배포
6. 전체 상태 확인이 흐름에서 배포 시간은 조금 늘어납니다. 하지만 실패했을 때 영향을 받는 서버 수와 판단해야 할 상태 수가 줄어듭니다. 운영에서는 이 차이가 배포 시간 몇 분보다 크게 작동했습니다.
AWX와 Ansible을 선택한 이유
이 시점의 문제는 인프라를 새로 만드는 것이 아니었습니다. 이미 존재하는 서버에 어떤 설정을 적용하고, 어떤 순서로 애플리케이션을 교체할지를 제어하는 것이 핵심이었습니다.
그래서 Terraform처럼 리소스 선언에 강한 도구보다, Ansible과 AWX처럼 기존 서버를 대상으로 절차를 실행하고 결과를 남기는 도구가 더 맞았습니다.
- 서버별 실행 순서를
serial: 1로 강제할 수 있었습니다. - 배포 작업의 입력값과 실행 이력을 AWX Job으로 남길 수 있었습니다.
- GitHub Actions에는 이미지 태그 전달과 Job 실행만 남길 수 있었습니다.
- Playbook에서 템플릿, compose 반영, health check를 같은 흐름으로 묶을 수 있었습니다.
도구 이름보다 책임 경계를 먼저 나눴습니다. GitHub Actions는 산출물을 만들고, AWX는 그 산출물을 어떤 서버에 어떤 순서로 적용할지 담당하도록 나눴습니다.
배포 관측은 거창한 시스템보다 기본 필드가 먼저였습니다
배포 중 문제가 생겼을 때 필요한 정보는 생각보다 단순했습니다. 어느 서버가 어떤 버전인지, 어느 단계에서 실패했는지, 그 시점에 어떤 오류가 반복됐는지 확인할 수 있어야 했습니다.
이 값들이 있어야 배포 실패를 “서버 전체 문제”가 아니라 “특정 버전 또는 특정 인스턴스 문제”로 좁힐 수 있습니다. 배포 자동화는 명령을 대신 실행하는 도구이기도 하지만, 같은 판단 지점을 매번 빠뜨리지 않게 만드는 장치이기도 했습니다.
다음 서버로 넘어가기 전 확인할 것
런치챗에서 필요했던 것은 더 빠른 배포가 아니었습니다. 배포 중에도 요청을 받을 수 있는 서버를 남기고, 실패했을 때 변경 범위를 작게 유지하는 구조가 더 중요했습니다.
병렬 배포는 빠르지만 실패 범위를 넓혔고, 롤링 배포와 AWX는 배포 시간을 조금 늘리는 대신 판단해야 할 상태를 줄였습니다. 여기서 속도보다 앞에 둔 것은 배포 중에도 요청을 받을 서버를 남겨 두고, 이상이 보이면 다음 인스턴스로 넘어가지 않는 안전장치였습니다.
- 배포 중에도 요청을 받을 수 있는 서버가 남아 있어야 합니다.
- 첫 번째 서버 검증에 실패하면 다음 서버는 건드리지 않아야 합니다.
- readiness는 프로세스 생존이 아니라 실제 요청 처리 준비 상태를 기준으로 봐야 합니다.
- 빌드는 GitHub Actions, 배포 순서와 실행 이력은 AWX/Ansible이 맡도록 책임을 나눠야 합니다.
- 배포 직후에는 인스턴스별 버전, readiness, 5xx, 주요 응답 시간, 반복 예외 로그를 함께 봐야 합니다.
결과적으로 배포는 “서버를 재시작하는 일”에서 트래픽을 옮기고, 준비되지 않은 인스턴스를 다음 단계로 넘기지 않는 절차가 됐습니다. 다음 배포를 볼 때도 확인 순서는 같습니다. 인스턴스별 버전이 맞는지, readiness가 실제 요청 처리 준비 상태를 반영하는지, 첫 번째 서버에서 5xx와 반복 예외가 늘지 않는지 확인한 뒤 다음 서버로 넘어가야 합니다. 롤링 배포의 핵심은 한 번에 덜 바꾸는 것이 아니라, 이상이 보였을 때 멈출 수 있는 지점을 만드는 것입니다.